A simple Framework for Contrastive Learning of Visual Representations
An overview of the paper “A simple Framework for Contrastive Learning of Visual Representations”. The authors propose a new approach for contrastive learning of visual representations. All images and tables in this post are from their paper. The authors show the following points in the paper:
- Composition of multiple data augmentation operations is crucial in defining the contrastive prediction tasks that yield effective representations. Moreover, unsupervised contrastive learning benefits from stronger data sugmentation than supervised learning.
- Introducing a learnable nonlinear transformation between the representation and contrastive loss substantially improves the quality of learned representations.
- Representation learning with contrastive cross entropy loss benefits from normalized embeddings and an appropriately adjusted temperature parameter.
- Contrastive learning benefits from larger batch sizes and longer training compared to its supervised counterpart. Like supervised learning, contrastive learning benefits from deeper and wider networks.
Summary of proposed Approach.
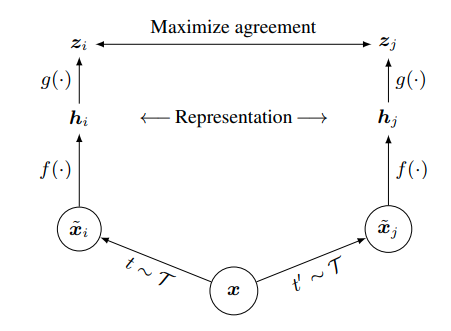
Method
The Contrastive Learning Framework
SimCLR learns representations by maximizing agreement between differently augmented views of the same data example via contrastive loss in the latent space.
- A stochastic data augmentation module that transforms any given data example randomly resulting in two correlated views pf the same example, denoted by
and
which we consider a positive pair.
- A neural network based econder
that extracts representation vectors from augmented samples such as the Resnet model. Here,
and
.
- A small neural network
that maps representations to the space where contrastive loss is applied. This is a step, which proves to be beneficial to the SimCLR model.
- We then apply the contrastive loss function on the new representation
.
Training with Large Batch Size
Here, they vary the training batch size . Training with large batch size may be unstable when using standard SGD/Momentum with linear learning rate scaling. To stabilize the training, they use the LARS optimizer for all batch sizes.
Evaluation Protocol
To evaluate learned representations, a linear classifier is trained on top of the frozen base network, and test accuracy is used as a procy for representation quality. Beryond linear evaluation, they also compare against state-of-the-art on semi-supervised and transfer learning.