Barlow Twins- Self-Supervised Learning via Redundancy Reduction
An overview of the paper “Barlow Twins- Self-Supervised Learning via Redundancy Reduction”. Self-supervised learning is rapidly closing the gap with supervised learning methods on large vision benchmarks. A successful approach is to learn representations which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant solutions. Most current methods avoid these trivial solutions by careful implementation details. In this paper, the authors propose an objective function that naturally avoids such collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making them as close to identity as possible. This causes the representation vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. All images and tables in this post are from their paper. Barlow in his paper, hypothesized that the goal of sensory processing is to recode highly redundant sensory inputs into a factorial code (a code with statistically independent components).
Brief Overview of Methodology
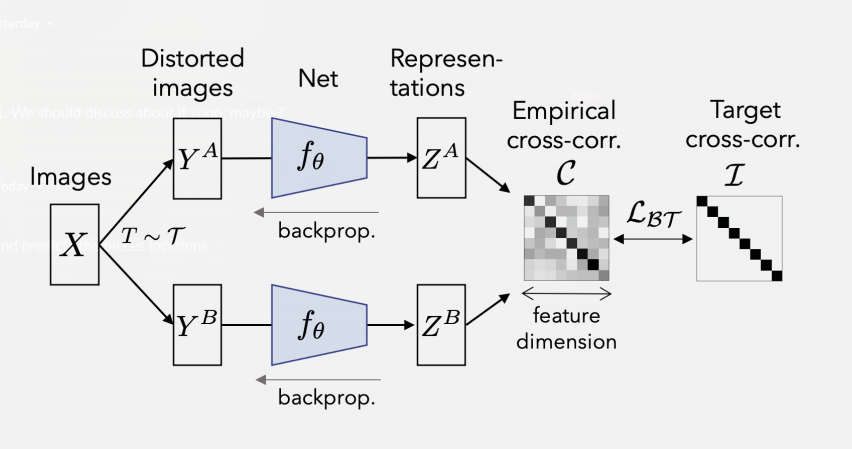
Methodology
Like other methods for Semi-Supervised Learning, Barlow Twins operates on a joint embedding of distorted images. More specifically, it produces two distorted views for all images of a batch sampled from a dataset. The distorted views are obtained via a distribution of data augmentations
. The two batches of distorted views
and
are then fed to a function
, typically a deep network with trainable parameters
, producing batches of representations
and
respectively. To simplify notations,
and
are assumed to be mean-centered along the batch dimension, such that each unit has mean output 0 over the batch.
Barlow twins uses an innovative loss function :
where is a positive constant trading off the importance of the first and second terms of the loss, and where
is the cross-correlation matrix computed between the outputs of the two identical networks along the batch dimension:
where indexes batch samples and
,
index the vector dimension of the networks’ outputs.
Intuitively, the invariance term of the objective, by trying to equate the diagonal elements of the cross-correlation matrix to 1, makes the representation invariant to distortions applied. The redundancy reduction term, by trying to equate the off-diagonal elements of the cross-correlation matrix to 0, decorrelates the different vector components of the representation. This decorrelation reduces the redundancy between output units so that the output units contatin non-redundant information about the sample.