Curriculum in Gradient-Based Meta-Reinforcement Learning
An overview of the paper “Curriculum in Gradient-Based Meta-Reinforcement Learning”. In this paper, the authors propose a method to construct tasks from unlabeled data in an automatic way and run meta-learning over the constructed tasks. All images and tables in this post are from their paper. With the wrong curriculum, agents suffer the effects of meta-overfitting, shallow adaptation, and adaptation instability.
Brief Overview of Methodology
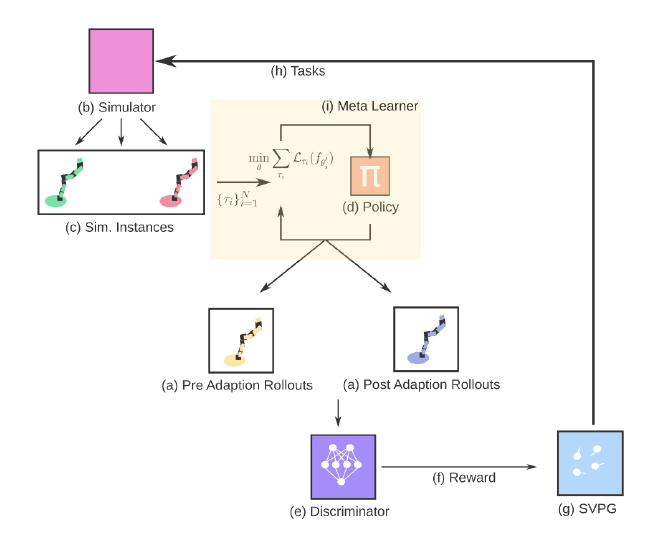
Meta-ADR proposes tasks to a meta-RL agent, helping learn a curriculum of tasks rather than uniformly sampling them from a set distribution. A discriminator learns a reward as a proxy for task-difficulty, using pre and post-adaptation rollouts as input. The reward is used to train SVPG particles, which find the tasks causing the meta-learner the most difficulty after adaption. The particles propose a diverse set of tasks, trying to find the tasks that are currently causing the agent the most difficulty.
As pointed out by the author the task distribution turns out to be an extremely sensitive hyperparameter in Meta-RL: too “wide” of a distribution leads to underfitting, with agents unable to specialize to the given target task even with larger numbers of gradient steps; too “narrow”, and we see poor generalization and adaptation to even slightly out-of-distribution environments.
Active Domain Randomization
Domain Randomization is a useful zero-shot technique for transferring robot policies from simulation to real hardware, uniformly samples randomized environments (effectively, tasks) that an agent must solve. ADR improves DR by learning an active policy that proposes a curriculum of tasks to train an inner-loop, black-box agent. These models use Stein Variational Policy Gradient (SVPG) to learn a set of parameterized particles, that proposes randomized environments which are subsequently used to train the agent. SVPG benefits from both the Maximum-Entropy RL framework and a kernel term that repulses similar policies to encourage particle, and therefore task diversity. This allows SVPG to hone in on regions of high reward while maintaining variety, which allows ADR to outperform many existing methods in terms of performance and generalization. To train the particles, ADR uses a discriminator to distinguish between trajectories generated in a proposed randomized environment and those generated by the same policy in a default, reference environment. Intuitively, ADR is optimized to find environments where the same policy produces different behavior in the two types of environments, signalling a probable weakness in the policy when evaluated on those types of randomized environments.
Method
While curriculum learning has had success in scenarios where task-spaces are structured, learning curricula in unstructured task-spaces, where an intuitive scale of difficulty might be lacking, is an understudied topic. A natural fit in the meta-learning scenario would be to somehow use the qualitative difference between the pre and post-adaptation trajectories. Like a good teacher with a struggling student, the curriculum could shift towards where the meta-learner needs help. For example, tasks in which negative adaptation occurs, or where the return from a pre-adapted agent is higher the post-adapted agent, would be prime tasks to focus on for training. Rather than using a reference environment as in ADR, the authors ask the discriminator to differentiate between the pre and post-adaptation trajectories. If a particular task generates trajectories that can be distinguished by the discriminator after adaptation, we focus more heavily on these tasks by providing the high-level optimizer, parameterized by Stein Variational Policy Gradient, a higher reward.
Algorithm
