Diversity is all you need - Learning Skills without a Reward Function
An overview of the paper “Diversity is all you need”. The author presents a method for reinforcement learning called DIAYN. All images and tables in this post are from their paper.
Introduction
Reinforcement learning has inherently been hard due to its reliance on human supervision. Reinforcement learning depends on human supervision for number of ways:
- We need humans to design reward functions to tell our robots what’s good and what’s bad.
- We need humans to help break complex tasks to easier tasks. Could be related to creating reward functions, or using action space.
- We need humans to tune huperparameters of RL algorithms.
- We need humans to reset the environments.
- We need humans to keep robots away from dangerous states. Furthermore, we also need to define these “dangerous states”.
- We also need humans to design a curriculum of tasks so we can learn over time.
This paper focuses on how to learn useful skills without relying on any human supervision. There is a spillover to other issues with this progress.
Skills
Skills are defined as the actions a given robot can make in an environment. However, the set of skills might become more complex as the robot becomes more complex. The pool of skills of a given robot would be unknown. In this work, the authors discuss an algorithm that helps learn a set of skills or behaviors for a certain environment/robot.
Properties of good skills
We want three unique characteristics to call a given behavior a good skill:
- Exploration: We want skills that span a wide of behaviors that go to various parts of the state space. Maybe there will be one skill that does nothing. But, we want everything else to do more interesting skills.
- Predictability: We want the skills that we learn to be predictable. We want to know, given that I am executing the skill “77”, what behavior is the agent going to perform. This is particularly important in hierarchical reinforcement learning.
- Interpretability: If we watch a robot executing a certain action, we should be able to predict which skill the robot is trying to do. This remains a key to developing the below algorithm.
The main of the paper is to learn a set of skills that is as diverse as possible. A singleton skill is neither good nor bad, what we care about is how the two skills link to one another. One question that is obvious is, what does the author mean by “as diverse as possible”. Previous approaches usually address this as a distance metric, which might not be applicable in higher dimensional space.
DIAYN
Note that the algorithm have no explicit reward functions. What we use is a pseudo-reward functions coming from the prediction by the discriminator instead of the environment. Hence, it does work as an RL problem with a small twist to it.
Another important point to note is that, we predict the skill based on the resulting state, and not the action taken. The authors mention that predicting the skill from the state-action pair might not be fruitful, as the model would become powerful enough to ignore states altogether, and predict only using actions. Since, for most RL robots, we care about the states they reach, and not exactly how they reach there. While in theory, the two should converge to similar behavior, in practice, using only states works significantly better.
The main idea is to maximize number of bits sent one of the networks.
Summary of proposed approach.
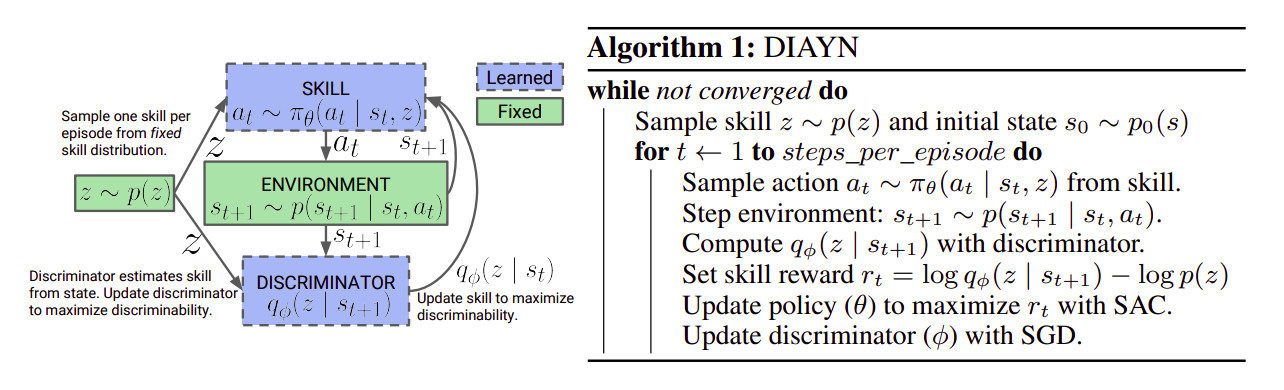
How does the algorithm work?
The method proposed in the paper is an unsupervised skill discovery method, and is built of three core ideas:
- For skills to be useful, we want the skill to dictate the states that the agent visits. Different skills should visit different states, and hence be distinguishable.
- We want to use states, not actions to distinguish skills, since actions that do not affect the environment are not visible to an outside behavior.
- We encourage exploration and incentivize the skills to be as diverse as possible by learning skills that act as randomly as possible.
The objective of the model is constructed using information theory: and
are random variables for states and actions, respectively;
is a latent variable, on which we condition our policy; we refer to the policy conditioned on a fixed
as a “skill”.
and
refer to mutual information and Shannon entropy, both computed with base
. In the objective, we maximize the mutual information between skills and states
, to encode the idea that the skill should control which states the agent visits. Conventionally, this mutual information dictates that we can infer the skill from states visited. To ensure that states, not actions are used to distinguish skills, we minimize the mutual information between skills and actions given the state,
. Viewing all skills together with
as a mixture of policies, we maximize the entropy
of this mixture policy.
In summary, we maximize:
The first term encourages our prior distribution over to have high entropy. We fix
to be uniform in our approach, guaranteeing that it has maximum entropy. The second term suggests that it should be easy to infer the skill
from current state. The third term suggests that each skill should act as randomly as possible, which we achieve by using a maximum entropy policy to represent each skill.
Experiments
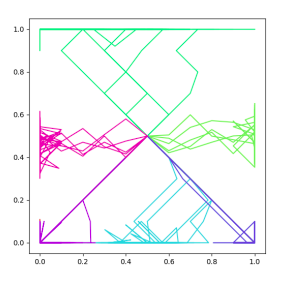
2-D Navigation Task
As a very small scale experiment, the authors apply their approach on a 2D navigation task, where the agent starts in the center of the room and then can move up-down, left-right until it hits one of the walls. We notice that diferent skills, denoted by different colors, do go to different regions. The skills learned do show the properties of exploration, predictability and interpretability.
2D Navigation task.
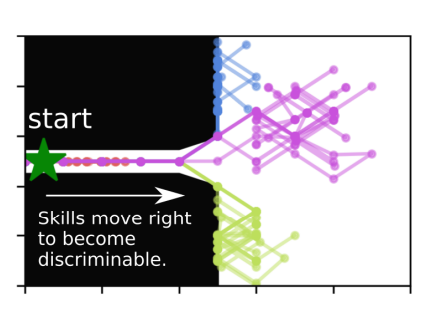
Overlapping Skills
This is also a 2D navigation task which all start at the hallway. Furthermore, when the skills are in the highway, they all look identical to one another because they cannot take any actions to differentiate themselves. One important point to highlight, is that the skills are made more diverse in the future, and not the present!
Overlapping task.
Conclusion
In this paper, the authors present DIAYN, a method for learning skills without reward functions. We show that DIAYN learns diverse skills for complex tasks, often solving benchmark tasks with one of the learned skills without actually receiving any task reward. We further proposed methods for using the learned skills (1) to quickly adapt to a new task, (2) to solve complex tasks via hierarchical RL, and (3) to imitate an expert. As a rule of thumb, DIAYN may make learning a task easier by replacing the task’s complex action space with a set of useful skills.