Efficient Estimation of Word Representations in Vector Space
An overview of the paper “Efficient Estimation of Word Representations in Vector Space”. The main goal of this paper is to introduce techniques that can be used for learning high-quality word vectors from huge data sets with billions of words, and with millions of words in the vocabulary. All images and tables in this post are from their paper.
Model Architectures
Many different types of models were proposed for estimating continuous representations of words, including the well-known Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA). In this paper, we focus on distributed representations of words learned by neural networks, as it was previously shown that they perform significantly better than LSA for preserving linear regularities among words. LDA moreover becomes computationally very expensive on large data sets.
Feedforward Neural Net Language Model (NNLM)
At the input layer, previous words are encoded using 1-of-V coding, where
is size of the vocabulary. The input layer is then projected to a projection layer
that has dimensionality
, using a shared projection matrix. In our models, we use hierarchical softmax where the vocabulary is represented as a Huffman binary tree. Huffman trees assign short binary codes to frequent words, and this further reduces the number of output units that need to be evaluated.
Recurrent Neural Net Language Model (RNNLM)
Recurrent neural network based language model has been proposed to overcome certain limitations of the feedforward NNLM, such as the need to specify the context length (the order of the model ), and because theoretically RNNs can efficiently represent more complex patterns than the shallow neural networks. The RNN model does not have a projection layer; only input, hidden and output layer. This allows the recurrent model to form some kind of short term memory, as information from the past can be represented by the hidden layer state that gets updated based on the current input and the state of the hidden layer in the previous time step.
Parallel Training of Neural Networks
The framework allows us to run multiple replicas of the same model in parallel, and each replica synchronizes its gradient updates through a centralized server that keeps all the parameters.
New Log-linear Models
The main observation from the previous section was that most of the complexity is caused by the non-linear hidden layer in the model. While this is what makes neural networks so attractive, the authors decided to explore simpler models that might not be able to represent the data as precisely as neural networks, but can possibly be trained on much more data efficiently.
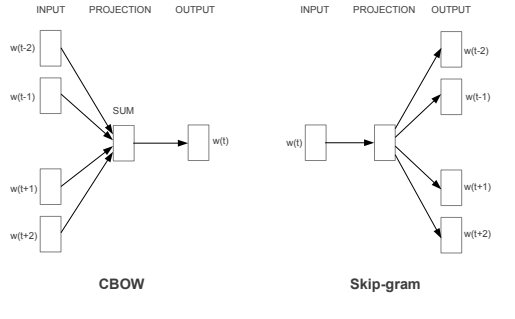
Continuous Bag-of-Words Model
This architecture is similar to the feedforward NNLM, where the non-linear hidden layer is removed and the projection layer is shared for all words (not just the projection matrix); thus, all words get projected into the same position (their vectors are averaged). The authors call this architecture a bag-of-words model as the order of words in the history does not influence the projection.
Continuous Skip-gram Model
This architecture is similar to CBOW, but instead of predicting the current word based on the context, it tries to maximize classification of a word based on another word in the same sentence. More precisely, we use each current word as an input to a log-linear classifier with continuous projection layer, and predict words within a certain range before and after the current word. We found that increasing the range improves quality of the resulting word vectors, but it also increases the computational complexity. Since the more distant words are usually less related to the current word than those close to it, we give less weight to the distant words by sampling less from those words in our training examples.
New model architectures. The CBOW architecture predicts the current word based on the context, and the Skip-gram predicts surrounding words given the current word.