Fixing the train-test resolution discrepancy
An overview of the paper “Fixing the train-test resolution discrepancy”. The author points out data-augmentation is key to the training of neural networks for image classification. This paper first shows that existing augmentations induce a significant discrepancy between the size of objects seen by the classifier at train and test time: in fact, a lower train resolution improves the classification at test time. All images and tables in this post are from their paper. The authors then propose a simple strategy to optimize the classifier performance, that employs different train and test resolutions.
Introduction
The motivation behind this paper is quite straightforward. In image recognition, the current best training practice is to extract a rectangle with random coordinates from the imagem which artificially increases the amount of training data. This region is called the Region of Classification (ROC), which is then resized to obtain a crop of fixed size (in pixels) that is fed to the CNN. At test time, the ROC is instead set to a square covering the central part of the image, which results in the extraction of the so called “center crop”. This reflects the bias of photographers who tend center important visual content. Thus, while the crops extracted at training and test time have the same size, they arise from different RoCs, which skews the distribution of data seen by the CNN.
Brief Overview of Methodology

Selection of the image regions fed to the network at training time and testing time, with typical data-augmentation. The red region of classification is resampled as a crop that is fed to the neural net. For objects that have as similar size in the input image, like the white horse, the standard augmentations typically make them larger at training time than at test time (second column). To counter this effect, we either reduce the train-time resolution, or increase the test-time resolution (third and fourth column). The horse then has the same size at train and test time, requiring less scale invariance for the neural net. This approach only needs a computationally cheap fine-tuning.
Data augmentation is routinely employed at training time to improve model generalization and reduce overfitting. Typical transformations include: random-size crop, horizontal flip and color jitter. The accuracy is also improved by combining multiple data augmentations at test time, although this means that several forward passes are required to classify one image. For example, using ten crops (one central, and one for each corner and their mirrored versions). Another performance boosting strategy is to classify an image by feeding it at multiple resolutions, and averaging the predictions. Most recently, multi-scale strategies such as the future pyramid network have been proposed to directly integrate multiple resolutions in the network, both at train and test time, with significant gains in category-level detection.
Feature pooling is also routinely employed in these models. Recent approaches employs p-pooling instead of average pooling to adapt the network to test resolutions significantly higher than the training resolution. The authors show that this improves the network’s performance.
Region Selection and Scale statistics
Applying a CNN classifier to an image generally requires to pre-process the image. One of the key steps involves selecting a rectangular region in the input image, which we call the Region of Classification (RoC). The RoC is then extracted and resized to a square crop of size compatible with the CNN. While this process in simple, in practice it has two subtle but significant effects on how the image data is presented to the CNN:
- The resizing operation chnages the apparent size of the objects in the image as mentioned earlier. This is important because, CNNs fo not have a predictable response to a scale change.
- The choice of different crop sizes has an effect on the statistics of the network activations, especially after global pooling layers.
Scale and apparent object size
If a CNN is to acquire a scale-invariant behavior for object recognition, it must learn it from the data. However, resizing input images in pre-processing changes the distribution of objects sizes. Since different pre-processing protocols are used at training and test time, the size distribution differs in the two cases.
By logic, while modelling the objects of the 3D world onto a 2D image, the apparent size of the objects in inversely proportional to their distance from the camera. For example, if we model a 3D object as an upright square of height and width (depth is irrelevant). The 3D object sits at a distance
from the camera and is fronto-parallel to it. Hence, its image is a
rectangle, where the apparent size
is given by
where f is the focal length of the camera.
Now, consider the effect of rescaling images on the apparent size of objects. If an object has an extent of
pixels in the input image, and if
is the scaling factor between input image and the crop, then by the time the object is analysed by the CNN, it will have the new size of
pixels. The scaling factor
is determined by the pre-processing protocol. As a prototypical augmentation protocol, the authors consider a RandomResizedCrop which takes as input an
image, selects a RoC at random, and resizes the latter to output a
crop. Assuming a square image, and that
, the scaling factor from imput image to output crop is given by:
This way, the pro-processing standardizes the apparent size, which otherwise would depend on the input resolution. This is important as networks do not have built-in scale invariance.
Scale and activation statistics
In addition to affecting the apparent size of objects, pre-processing also affects the activation statistics of the CNN, especially if its architecture allows changing the size of the input crop. Changing the size of input crop strongly affects the activation statistics of the last layer. This simple statistical observations shows that if the distribution of activations changes at test time, the values are not in the range that the final classifier layers (linear & softmax) were trained for.
Cumulative density function of the vectors components on output of spatial average pooling operator.
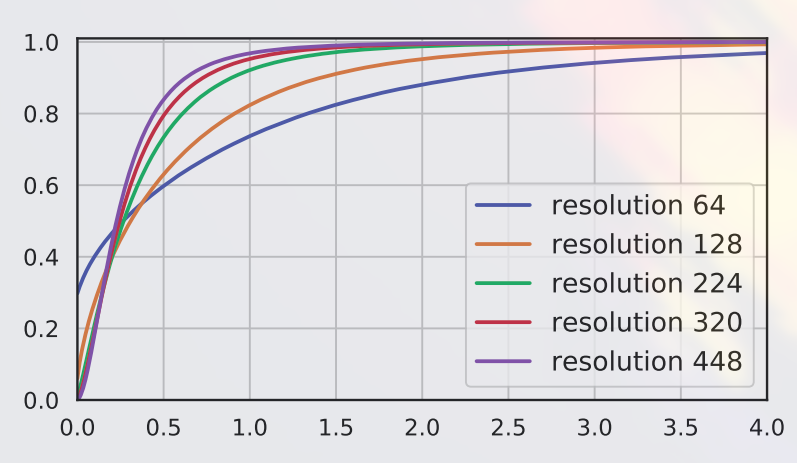
Larger test crops result in better accuracy
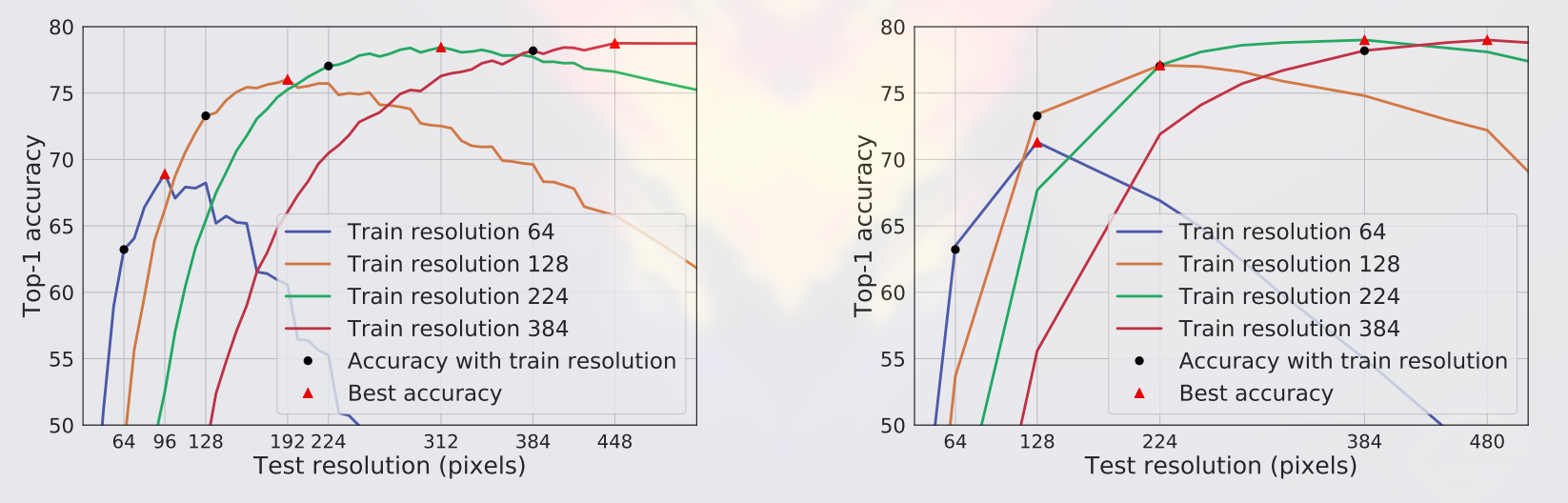
Despite the fact that increasing the crop size affects the activation statistics, it is generally beneficial for accuracy, since as discussed before it reduces the train-test object size mismatch.
Top-1 accuracy of the ResNet-50 according to the test time resolution
Methodology
We use the above equation to change the apparent object sizes during training and testing. If the size of the intermediate image is increased by a factor
then at test time, the apparent size of the objects is increased by the same factor. This equalizes the effect of the training pre-processing that tends to zoom on the objects. If we increase
with
fixed means looking at a smaller part of the object. This is not ideal: the object to identify is often well framed by the photographer, so the crop may show only a detail of the object or miss it altogether. Hence, in addition to increasing
, we also increase the crop size
to keep the ratio
constant.
Once we have done this, we have selected the “correct” test resolution for the crop but we have skewed activation statistics. Hereafter they explore two approaches to compensate for this skew.
- Parametric Adaptation: In this approach, they fit the output of the acerage pooling layer with a parametric Freschet distribution at the original
and final
resolutions. This is then used as the activation function after the pooling layers. This approach provides a measurable but limited improvement on accuracy, probably because the model is too simple and does not differentiate the distributions of different components going through the pooling operator.
- Adaptation via fine-tuning: In this approach, increasing crop resolution at test time is effectively a domain shift. A natural way to compensate for this shift is to fine-tune the model.
Conclusion
here, the authors have studied extensively the effect of using different train and test scale augmentations on the statistics of natural images and of the network’s pooling activations. They have further shown that, by adjusting the crop resolution and via a simple and light-weight parameter adaptation, it is possible to increase the accuracy of standard classifiers significantly, everything being equal otherwise.