How to represent part-whole hierarchies in neural network
An overview of the paper “How to represent part-whole hierarchies in neural network”. The authors propose a single idea about representation which allows advances made by several different groups to be combined into an imaginary system called GLOM. All images and tables in this post are from their paper.
The idea is to combine three recent advances in neural networks which has not yet been implemented. But these three ideas seem to fit together very naturally.
- The first idea is Transformers which has been used for moedling natural language.
- The second idea is Unsupervised Learning of Visual representations via mutual agreement.
- The third idea is Generative models of images that use implicit functions.
The idea behind GLOM is to create a system that is much more like human perception than current deep nets.
The psychological reality of the part-whole hierarchy and coordinate frames
In this section, the author attempts to convince us that when people perceive objects, they use coordinate frames (rectangual coordinate frames) and they pass objects into part whole hierarchies.
The cube demonstration (Hinton 1979)
- Imagine a wire-frame cube resting on a table top
- Imagine the body diagonal that goes from the front bottom right corner, through the center of the cube to the top back left corner.
- Keeping the front bottom right corner on the table top, move the top back left corner until it is vertically above the front bottom right corner.
- Hold one finger-tip above the table to mark the top corner. With the other hand, point out the other corners of the cube.
The idea here is that most people only point out 4 other corners. If we use an unfamilar coordinate frame, we might have this issue with visualization. Most people preserve the idea of cube, and point out the four corners on the same level (preserving symmetry structure). The author uses this example to show that our mind inherently uses the coordinate frame, and upon shifting to a new unfamilar frame, we tend to forget where the objects are.
The very same arrangements of rods can be represented in quite different ways. The alternative percepts do not disagree, but they make different facts obvious. The take from this experiment is that whenever you form a mental image, you associate view-point information with the nodes in the structural description.
Why is it hard to make real neural networks learn part-whole hierarchies
- Each image could have different parse trees.
- Reak neural networks cannot dynamically allocate neurons to represent nodes in a parse tree. What a neuron does is determined by the weights on its connections and the weights change slowly.
Hence, it becomes difficult to use static neural networks to represent dynamic parse trees. ConvNets are very different from us. They use fine grained information and do not use any spatial information to make their decision, unlike us.
A brief introduction to transformers
Most standard neural networks, in order to activate a neuron, they take a scalar product of a vector of activity of the layer below, and a vector of weights of the neuron. Basically, we multiply activity with a weight. This is not very good at capturing covariance structure in an image. There is a different way of activating neurons, where we multiply activity with another activity. This gives us quite different properties. And this is what transformers do. In a transformer, it creates three vectors - a query, key and value. The query it has created is matched (scalar product) with other nearby words (in case of NLP product). Now, value of those high vectors contributes to the meaning of the given word, while being directly proportional to .
A brief introduction to contrastive learning of visual representations
Contrastive self-supervised learning uses the similarity between activity vectors produced from different patches of the same image as the objective. The author then introduces us to SimCLR which I have already covered previously. In brief, the idea is to take an image and create two different views of the same image. The idea is that the model should minimize the differences between embeddings of patches from the same image. and also maximize the differences between similar embeddings of patches from different images. The idea is that after unsupervised learning, we take the layer before the learned embeddings, and fit a linear classifier (i.e. a softmax).
This method works, but is not intuitively correct. If we two parts of the same scene, they need not contain the same class the image pertains to. What if one patch in an image contains parts of objects of class A and B, and other patch contains parts of objects of class A and C. We do not want the whole patch that contains A and B to match with the whole patch that contains A and C. We want to use some type of attention. We wants parts of the patch that contains A in the first patch, to match with parts of the patch that contains A in the second patch. We also want objects B and C of the two patches not to match.
Spatial Coherence
The original motivation for using agreement of the output vectors from different patches as an objective function was not classification. In GLOM, we discover spatial coherence using part-whole hierarchy. For eg. If you see a nose, and a mouth, and they are in the right relationship to make a face, then they are spatially coherent. GLOM isnt meant to be a whole of vision. We do not process the whole image at once, we use smaller patches of the image. The outer loop of vision involves looking around for patches in an intelligent way. Each of these patches is then fed to the same neural network.
Ways to represent part-whole hierarchies
- Symbolic AI - For each image, dynamically create a graph in which a node for a whole is connected to nodes for its parts.
- Capsules - Permanently allocate a piece of neural hardware for each possible node. For each image, activate a small subset of possible nodes and use dynamic routing to activate connections between whole and part nodes.
- GLOM - Use islands of agreement to represent nodes in the parse tree.
A biological inspiration
Every cell has a complete set of instructions for making proteins. The environment of the cell determines which proteins are actually expressed. So cells differ in their vector of protein expressions. The vectors are similar within an organ. It seems wasteful to duplicate all of the knowledge in every cell, but it is very convenient.
The analogy with vision
Image locations are like cells. Weights are like DNA. In a ConvNet, the weights are duplicated at every location. THe complete vector of neural activities centered on a location is like the vector of protein expressions in a cell. Objects are like organs, they are collections of cells with similar gene expression vectors.
Three adjacent levels of GLOM for one location.
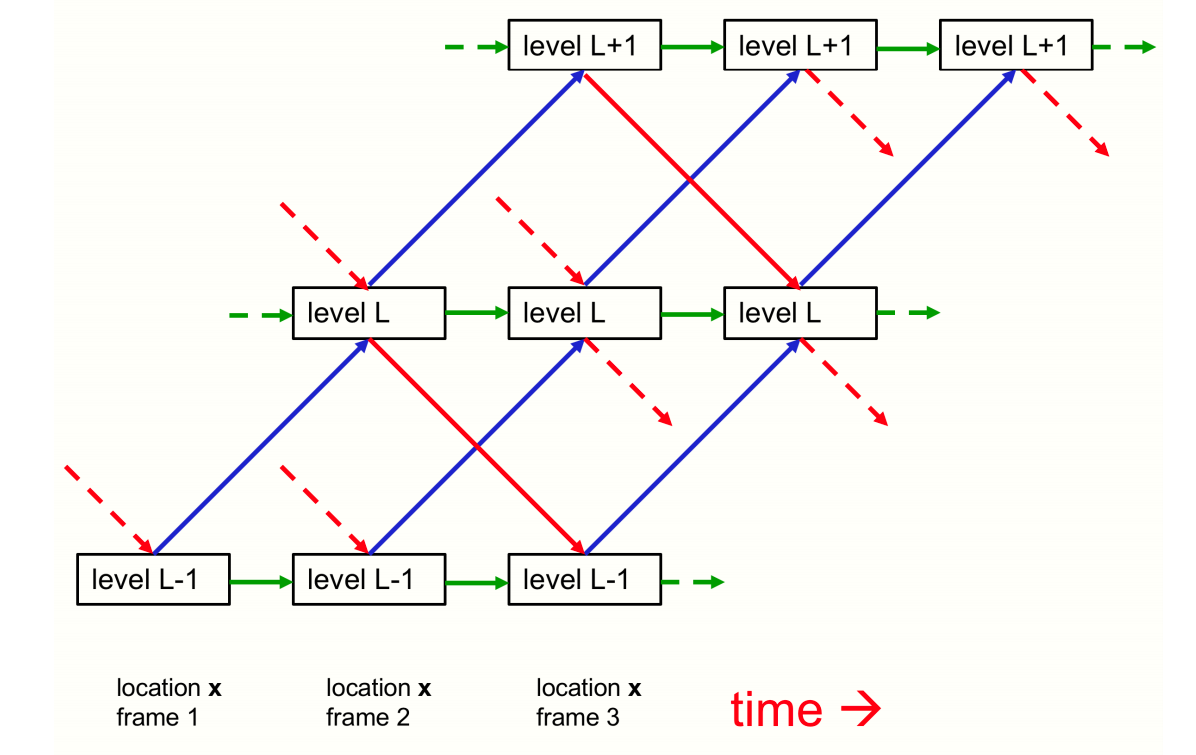
The idea is that at each location, we have seperate hardware. Instead of allocating hardware to things like a nose or mouth, we allocate hardware to a location (multiple levels at that). We deal a static image as a very boring video. At the bottom left corner, we give frame 1. From image pixels to , we represent what’s going on at location
. At level
, we might understand what sub-part(nostril) is there. Then, at level
, we want to represent what major part(nose) is there, and so on. Here, the activity comes from 3 different vectors as shown in the image. In addittion to this, there are interactions between different cells which are not shown in the above diagram.
The level
embedding at location
is an average of four contribution:
- The bottom-up contribution from the level
embedding at location
in the previous layer.
- The top-down contribution from the level
embedding at location embedding at location
in the previous layer.
- The attention weighted average of the level
embeddings at other locations in the previous layer. (Similar to echo-chamber)
- The previous embedding.
The embedding vectors for a row of locations in a single mid-level layer of GLOM.
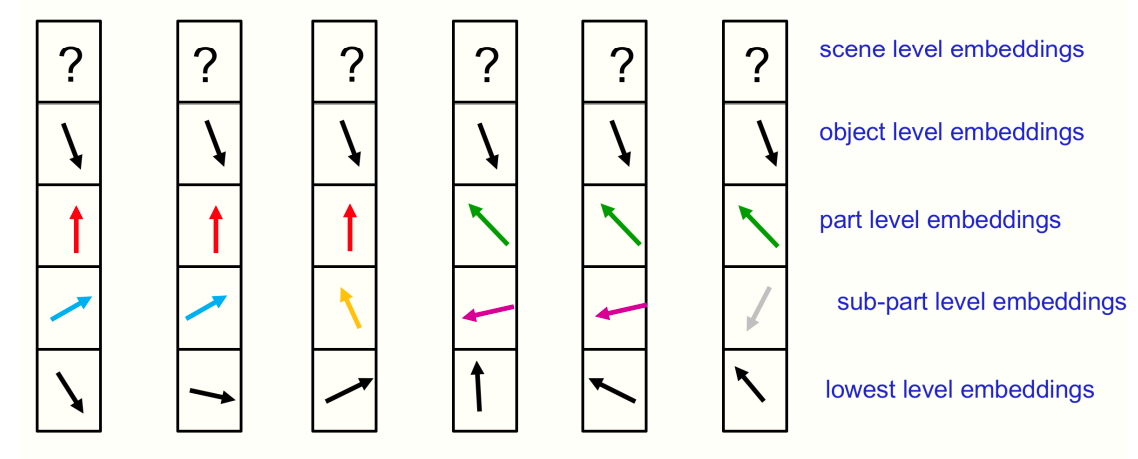
Here, each column is a different location, and boxes within each column is the level at the given location. What we hope to see is that at object level, there will be many locations that agree on what the overall object is. At the part level, not all might agree, which might denote parts such as nose, mouth, etc. The basic idea of GLOM is that we represent a parse tree by the relationship between these islands. The fact that all object-level-embeddings agree is a good inference of what the object is. When a face vector makes top-down predictions for the parts of the face, how can the same face vector make different predictions for locations in the nose and locations. The answer would be to use neural fields or implicit function. Instead of predicting a whole image from a code vector, an implicit function predicts one small location of the image when given the code vector and a representation of the coordinates of the location.
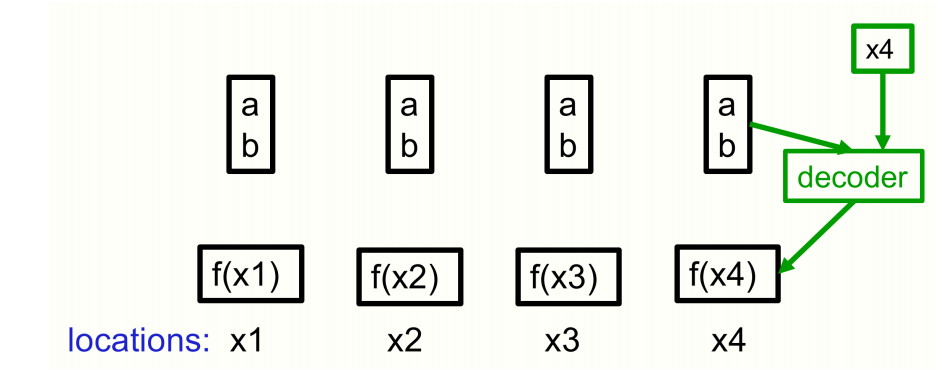
A very simple example of an implit function decoder
Suppose we have 4 pixels, in which the intensity increases linearly along the row, i.e.. We can make a code which is
which is fixed. For a new pixel, we can use this neural code and implicit function to predict its intensity.
S simple example of neural field.
Top-down prediction of the parts of a face
The object level embedding vector for a face contains viewpoint information about the spatial relationship between the intrinsic coordinate frame of the face and the coordinate frame of the camera or retina. Given the coordinates of a location in the image, the top down neural net can compute where that location is within the intrinsic coordinate frame of the face. So, the top-down net can compute which part goes at that image location. This allows it to predict the nose vector for locations within the nose and the mouth vector for locations within the mouth.
The attention-weightage average
The obvious way to train the model is to show an image with patches missing (similar to BERT). The islands are formed because the vector you get at one location is trying to agree with others that are similar in embedding. The level embedding at location
tries to agree with similar level
embeddings at other locations.
The attention weighted average of the level
embeddings at other locations,
uses weights proportional to
. This causes the level
embeddings to form islands of similar embeddings (Islands are echo chambers).
Deep end-to-end training
Given an image missing regions at the input, GLOM is trained to predict the uncorrupted image at its output. This is how BERT is trained to learn good embeddings for word fragments. But this objective alone will not make the embeddings form islands of similar embeddings at different locations. That is where contrastive learning becomes relevant.
At a given location, a neural net is making a prediction for an adjacent level in the next layer. So, level is getting an input from the top-down and botoom-up neural nets, and we want to train these nets. Each of these nets make a prediction, and then we average the predictions coming from similar representations at nearby locations using attention weighted average. We then want the top-down and bottom-up neural nets to agree with the average. So, we train such that the general consesus agrees with this weighted average, causing them to be better at forming islands.
There are mainly two reasons why islands, which learn similar embeddings, are not wasteful:
- As the network is settling down, it has to decide which location should have the same object, and which location have the same part. Having all the vectors available before they become identical is very useful for doing this search. Similar to creating clusters
- As you go up through the levels, we need longer range interactions. Instead of using every embedding, we can use one vector from the island, and ease our computation. This kind of sampling is already used in transformers for language processing.