How to train your MAML to excel in few-shot classification
An overview of the paper “How to train your MAML to excel in few-shot classification”.
The authors point out several key facets of how to train MAML to excel in few shot classification. Firstly, the authors find that MAML needs a large number of gradient steps in its inner loop update, which contradicts its common usage in few-shot classification. Secondly, the authors find that MAML is sensitive to the class label assignments during meta-testing. Specifically, the authors show that these permutations lead to a huge variance of accuracy, making MAML unstable in few-shot classification. Finally, the authors investigate several approaches to make MAML permutation-invariant among which meta-training a single vector to initialize all the weight vectors in the classification head performs the best. All images and tables in this post are from their paper.
Introduction
The problem of permutations in label assignments, and the illustration of UNICORN-MAML.
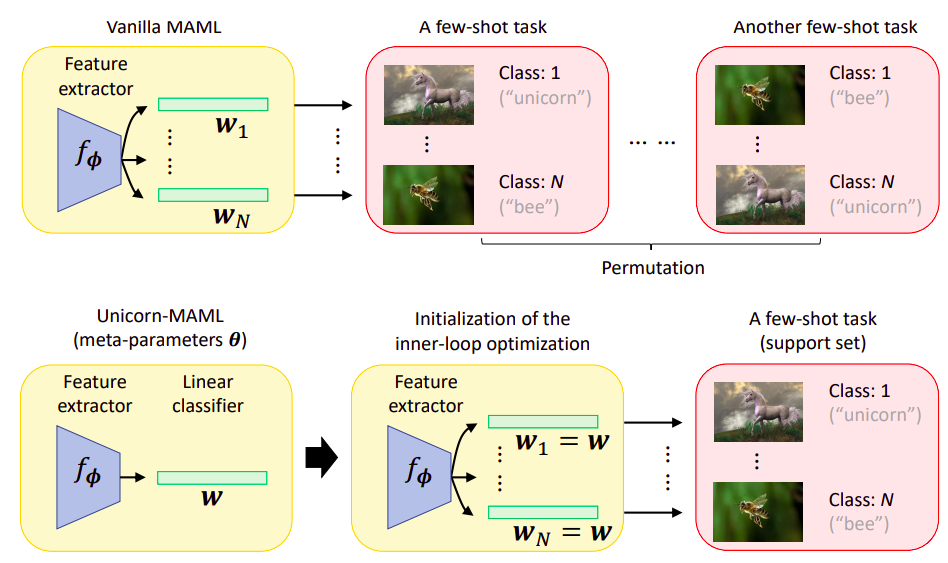
A vanilla MAML learns the initialization of and the
weight vectors
. Each of
is paired with the corresponding class label
of a few-shot task. A few shot task, however may consist of the same set of semantic classes but in different permutations of class label assignments, leading to a larger variance in meta-testing accuracy.
In contrast, the Unicorn-MAML proposed by this paper, besides learning
only learns only a single weight vector
and uses it to initialize all the
weight vectors
at the beginning of the inner loop. That is, Unicorn-MAML directly forces the learned model initialization to be permutation-invariant.
MAML needs a large number of inner loop gradient steps
MAML’s accuracy improves along with the increased number of gradient steps and achieves the highest around 15-20 steps, wchich are much larger than conventional usage of MAML. We attribute this to the behavior of the model initialization learned from mutually-exclusive tasks, which, without any further inner loop optimization, performs at the chance level on query examples, not only for meta-testing tasks but also for meta-training tasks. In other words, the initialized model needs many gradient steps to attain high accuracy.
MAML is sensitive to the permutations of class label assignments during meta-testing
While randomness has been shown crucial in meta-training to help MAML prevent over-fitting, the authors find that it makes the meta-testing phase unstable. Specifically, different permutations can lead to drastically different meta-testing accuracy - on average, the best permutation for each five-way one-shot task has higher accuracy than the worst permutation on datasets such as miniImageNet and tieredImageNet.
MAML needs to be permutation invariant
The authors propose a simple network alternative known as Unicorn-MAML. The solution is to meta-train only a single vector and using it to initialize the
linear classifier
performs well.
Conclusion
The authors perform an extensive study and create some guidelines for training MAML. Furthermore, the authors also propose a new training paradigm called UNICORN-MAML that helps create task agnostic learning, and allows the model to be invariant to permutation of the task samples.