Learning representations by mutual information estimation and maximization
An overview of the topic “Learning representations by mutual information estimation and maximization”. The authors propose a new algorithm called Deep InfoMAx(DIM) that learns representations by maximizing mutual information between an input and the output of a deep neural network encoder. All images and tables in this post are from their respective paper.
Introduction
One core objective of deep learning is to discover useful representations, and the simple idea explored here is to train a representation learning function, i.e. an encoder, to maximize the mutual information between its inputs and outputs. The authors furthermore show that structure matters: maximizing the average MI between the representation and local regions of the input (e.g. patches rather than the complete image) can greatly improve the representation’s quality. The main contributions are the following:
- They formalize Deep InfoMax (DIM), which simultaneously estimates and maximizes the mutual information between input data and learned high-level representations.
- Their mutual information maximization procedure can prioritize global or local information, which they show can be used to tune the suitability of learned representations for classification or reconstruction-style tasks.
- They use adversarial learning to constrain the representation to have desired statistical characteristics specific to a prior.
- They also introduced two new measures of representation quality which they use to bolster comparison of DIM to different unsupervised methods.
Deep InfoMax
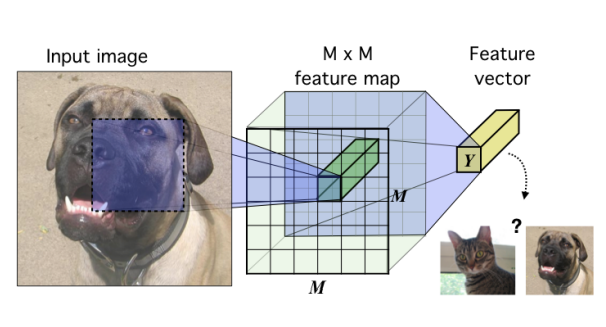
An image (for e.g.) is encoded using a convnet until it reaches a feature map of feature vectors corresponding to
input patches. These vectors are summarized into a single feature vector
. The goal is to train this network such that useful information avout the input is easily extracted from the high level features.
Base encoder model in the context of image data.
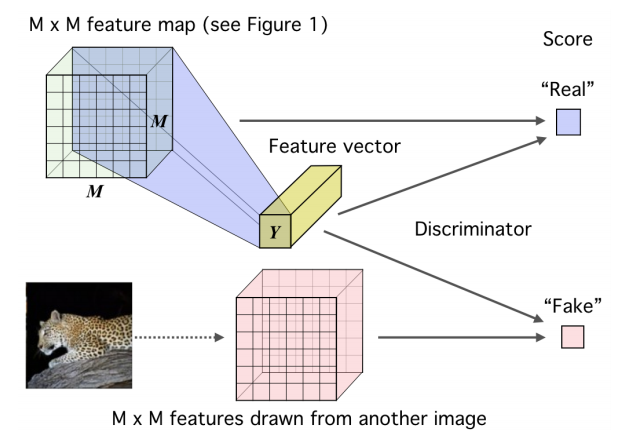
After this, we pass both the high level feature vector, , and the lower-level
feature map through a discriminator to get the score. Fake samples are drawn by combining the same feature vector with a
feature map from another image.
Deep InfoMax (DIM) with a global MI(X;Y) objective.
Mutual Information Estimation and Maximization
The approach follows Mutual Information Neural Estimation, which estimates mutual information by training a classifier to distinguish between samples coming from the joint,, and the product of marginals,
, of random variables
and
.
At a high level, they optimize by simultaneously estimating and maximizing:
where subscript demotes “global”.
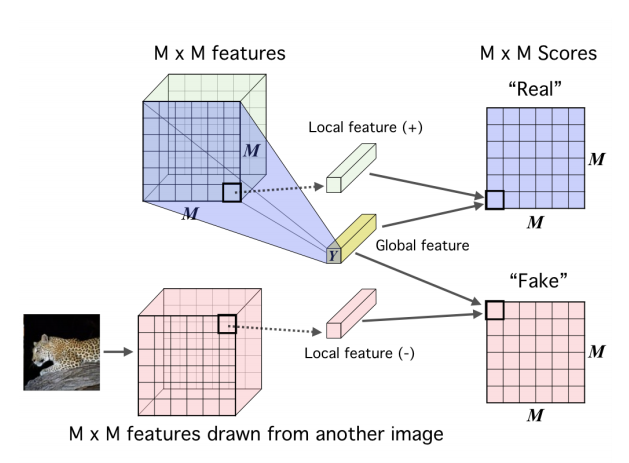
Local mutual information maximization
The objective of above function can be used to maximize MI between input and output, but ultimately this may be undesirable depending on the task. For example, trivial pixel-level noise is useless for image classification, so a representation may not benefit from encoding this information. In order to obtain a representation more suitable for classification, we can instead maximize the average MI between the high level representations and local patches of the image. Because the same representation is encouraged to have high MI with all the patches, this favours encoding aspects of the data that are shared across patches. First, we encode the input to a feature map, that reflect useful structure in the data (e.g. spatial locality). They then define the MI estimator on global/local pairs, maximizing the average estimated MI:
Maximizing mutual information between local features and global features.
Matching Representations to a prior distribution
DIM imposes statistical contraints onto learned representations by implicitly training the encoder so that the push-forward distribution matches a prior. This is done by training a discriminator to estimate the divergence, and the loss used is similar to the adversarial loss used in GAN. This approach is similar to what is done in adversarial autoencoders but without a generator. It is also similar to noise as targets, but trains the encoder to match the noise implicitly rather than using a prior noise samples as targets. With this, their model is able to learn better representations.