Learning to Teach with Dynamic Loss Functions
An overview of the paper “Learning to Teach with Dynamic Loss Functions”. In this work, the authors explore the possibility of imitating human teaching behaviors by dynamically and automatically outputting appropriate loss functions to train machine learning models. Different from typical learning settings in which loss function of a machine learning model is predefined and fixed, in our framework, the loss function of a machine learning model (student) is defined by another machine learning model (teacher). All images and tables in this post are from their paper.
Introduction
Teaching, which aims to help students learn new knowledge or skills effectively and efficiently, is important to advance modern human civilization. In human society, the rapid growth of qualified students not only relies on their intrinsic learning capability, but also, even more importantly, relies on the substantial guidance from their teachers. The duties of teachers cover a wide spectrum: defining the scope of learning (e.g., the knowledge and skills that we expect students to demonstrate by the end of a course), choosing appropriate instructional materials (e.g., textbooks), and assessing the progress of students (e.g., through course projects or exams). Effective teaching involves progressively and dynamically refining the teaching strategy based on reflection and feedback from students. In this loss function teaching framework, a teacher model plays the role of outputting loss functions for the student model (i.e., the daily machine learning model to solve a task) to minimize. The parameters of the teacher model can be automatically optimized in the teaching process. Through optimization, the teacher keeps improving its teaching model and consequently the quality of loss functions it outputs.
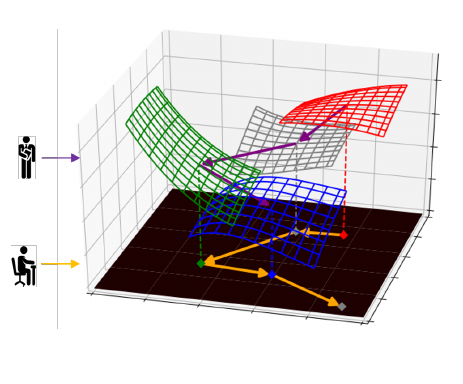
The student model is trained via minimizing the dynamic loss functions taught by the teacher model (yellow curve). The bottom black plane represents the parameter space of student model, and the four colored mesh surfaces denote different loss functions outputted via teacher model at different phases of student model training.
Model
From a technical point of view, the paper offers two distinctive concepts accourding to the authors:
- They leverage gradient based optimization method rather than reinforce- ment learning. This would be ideal since RL approaches would be unstable and require millions of samples to learn an optimal policy.
- It is difficult when the error information cannot be directly back propagated from the loss function, since they aim at discovering the best loss function for the machine learning models. They design an algorithm based on Reverse-Mode Differentiation (RMD) to tackle such a difficulty.
Their overall model called L2T-DLF includes two parts, a student model and teacher model.
Student Model
The student model hopes to learn an optimal by minimizing the loss function provided by the teacher network. The learnt student model is evaluated on the test dataset to obtain a score, which measures the similarity between the true output and predicted output. The loss function used by the model acts as the surrogate of
to evaluate the student model during it’s training process. This loss is given by
. It could be a simple linear model, or a deep learning network which learns this.
Teacher Model
A teacher model is responsible for setting the proper loss function to the student model by outputting appropriate loss function coefficients
. To cater for different status of student model training, we ask the teacher model to output different loss functions
at each training step
. To achieve that, the
status of a student model is represented by a state vector
at timestep
, which contains for example the current training/dev accuracy and iteration number. The teacher model, denoted as
, then takes
as inputs to compute the coefficients of loss function
t at
-th timestep as
, where
,
is the parameters of the teacher model. The goal of the teacher model is to maximize the performance of the induced student model on the stand-alone test/development dataset. The training process of the teacher model is described in more detail in the upcoming section.
Training Process of Teacher Model
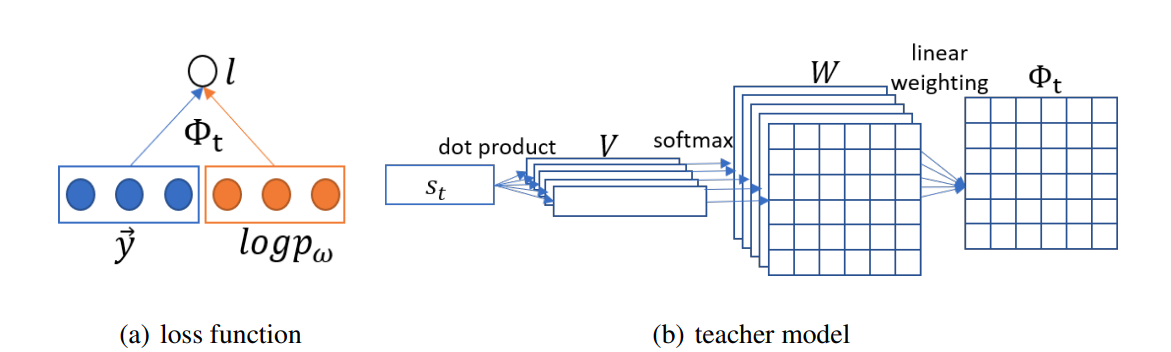
Left: the bilinear neural network specifying the loss function. Right: the teacher model outputting .
We update the teacher parameter to decrease the similarity/loss on the test dataset.
Conclusion
In contrast to expert designed and fixed loss functions in conventional machine learning systems, this paper studies how to learn dynamic loss functions so as to better teach a student machine learning model. Since loss functions provided by the teacher model dynamically change with respect to the growth of the student model and the teacher model is trained through end-to-end optimization, the quality of the student model gets improved significantly, as shown in their experiments from the paper.