MARL
An overview of the paper “Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms”. The authors propose a general overview of research in Multi-Agent reiforcement learning. All images and tables in this post are from their paper.
Introduction
MARl addresses the sequential decision-making problem of multiple autonomous agents that operate in a common environment, each of which aims to optimize its own long-term return by interacting with the environment and other agents. Algorithms in general can be placed into different groups:
- Cooperative: model collaborate to optimize a common long-term goal.
- Competitive: Zero-sum games
- Mix: General-sum returns
There are several challenges in MARL across different settings such as:
- Multidimensional goals leading to challenge in dealing with equilibrium points.
- Additional performance criteria beyond optimization, such as the efficiency of communication/coordination and robustness against potential adversarial agents.
- Concurrent policy improvement of “egoist” agents makes the environment non-stationary.
- The joint action space increases exponentially with the number of agents and may cause scalability issues.
- Information structure, such as how much information each agent has access to.
Background
Single-Agent RL
A RL agent is modeled to perform sequential decision-making by interacting with the environment usually defined as a MDP. A Markov decision process is defined by a tuple where:
is state space,
is action space.
is the transition probability of any state given action.
is the immediate reward received after the transition.
is the discount factor.
MDP is used to formalize the decision-making with full observability of state . The goal of MDP is to find a policy such that the discounted accumulated reward is maximized.
Multi-Agent RL
Both the evolution of the system state and the reward received by each agent influenced by the joint actions of all agents. Each agent now has its own long-term reward to optimize, which now becomes a function of the policies of all other agents. There are predominantly two theoretical frameworks for MARL:
- Markov/Stochastic games
- Extensive form games
Schematic diagrams of the system evolution of a MDPs, Markov game and Extensive-form game.
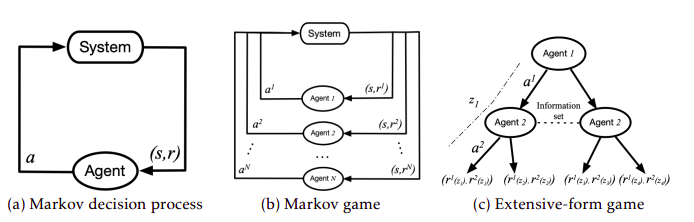
Markov/Stochastic Game
The Markov game is simply the extension of the MDPs to all the agents in the environment. The tuple is now simply defined as: .
To see how it works, assume at time
, each agent executes an action
and transition to
. The agents take their actions simultaneously for the given state. The goal of the agent is to optimize its own long-term reward, by finding the policy. The goal is to find the Nash equilibrium in MARL. As a standard learning goal for MARL, NE always exists for discounted rewards, but may not be unique in general.
- For fully cooperative setting, all the agents follow a common overall goal. This can also be viewed as a special case of Markov Potential games with potential function being the common accumulated reward. This allows the single-agent RL algorithms to be applied, if all agents are coordinated as one decision maker.
- In the (Partially) cooperative setting, we have a team-average reward. Agents are allowed to have a intrinsic reward. Such heterogeneity also necessitates the incorporation of communication protocols into MARL and the analysis of communication-efficient MARL algorithms.
- For fully competitive setting, we typically model as zero-sum Markov games. The scenario is mainly focussed on two agents. This leads to buliding a robust policy.
- In the mixed setting, each agent is self interested, and reward may be conflicting with others. Nash equilibrium is the most significant influence in these settings.
Extensive-Form games
Markov games can only handle the fully-observed case. A lot of MARL applications involve agents with only partial observability, i.e., imperfect information of the game. This is much more sophisticated that the previous setting. In this setting, we again have agents, and we add a chance of nature agent
, which has a fixed stochastic policy that specifies the randomness of the environment. Besides the set of all possible actions an agent can take, and
is the set of all possible histories, where each history is a sequence of actions taken from the beginning of the game. Let
denote the set of actions available after a nonterminal history
. Upon reaching terminal history, a utility is assigned to each agent called the identification function which specifies which agent takes the action at each history.
The assumption of perfect recall is commonly made in the literature, enables the existence of polynomial time algorithms for solving the game.
Challenges in MARL Theory
Despite a general model that finds broad applications, MARL suffers from several challenges from several challenges in theoretical analysis, in addition to those that arise in single-agent RL.
Non-Unique Learning Goals
Unlike single-agent RL, where the goal of the agent is to maximize the long-term return efficiently, the learning goals of MARL can be vague at times. Indeed, the goals that need to be considered in the analysis of MARL algorithms can be multi-dimensional. The most common goal, which has, however, been challenged, is the convergence to Nash equilibrium. By definition, NE characterizes the point that no agent will deviate from, if any algorithm finally converges. This is undoubtedly a reasonable solution concept in game theory, under the assumption that the agents are all rational, and are capable of perfectly reasoning and infinite mutual modeling of agents. However, with bounded rationality, the agents may only be able to perform finite mutual modeling. As a result, the learning dynamics that are devised to converge to NE may not be justifiable for practical MARL agents. Instead, the goal may be focused on designing the best learning strategy for a given agent and a fixed class of the other agents in the game.
Non-Stationarity
Another key challenge of MARL lies in the fact that multiple agents usually learn concurrently, causing the environment faced vy each individual agent to be non-stationary. In particular, the action taken by one agent affects the reward of other opponent agents, and the evolution of the state. As a result, the learning agent is required to account for how the other agents behave and adapt to the joint behavior accordingly. This invalidates the stationarity assumption for establishing the convergence of single-agent RL algorithms, namely, the stationary Markovian property of the environment such that the individual reward and current state depend only on the previous state and action taken.
Scalability Issue
To handle non-stationarity, each individual agent may need to account for the joint action space, whose dimension increases exponentially with the number of agents. This is also referred to as the combinatorial nature of MARL. Having a large number of agents complicates the theoretical analysis, especially the convergence analysis of MARL.
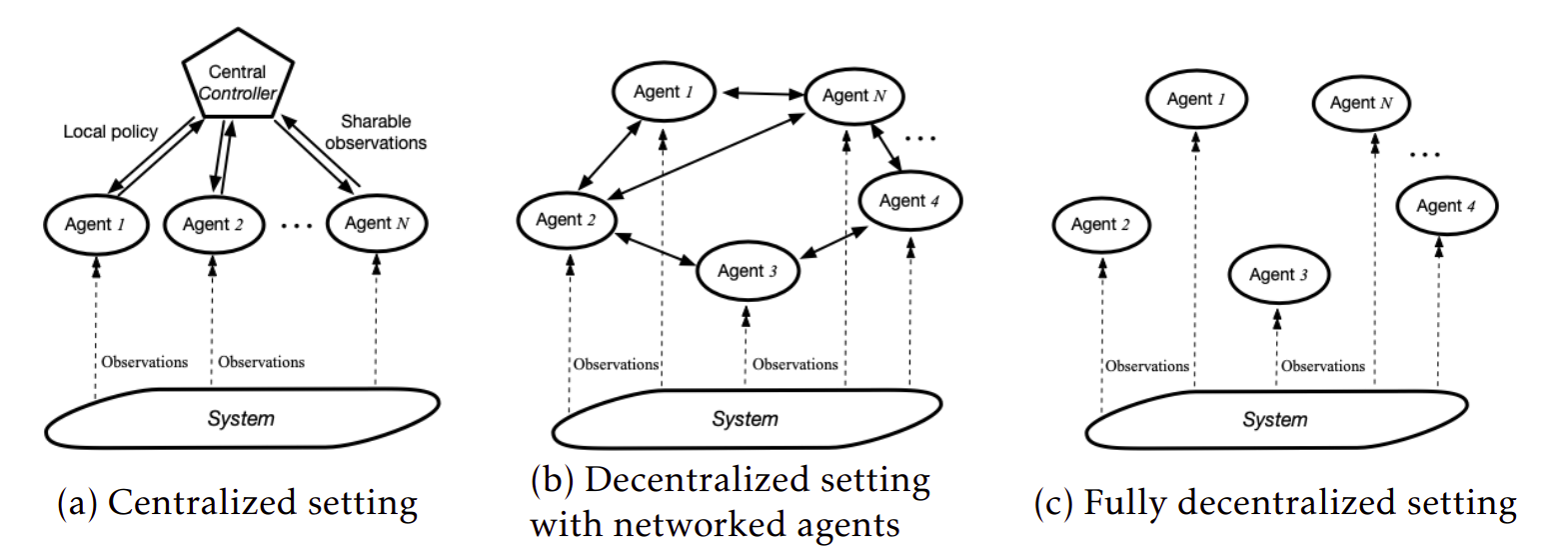
Various Information Structures
Compared to the single-agent case, the information structure of MARL, namely who knows what at the training and execution, is more involved. There are three broad categories in this regime:
- Centralized setting: All agents share complete information about states, actions, etc.
- Fully decentralized setting: Agents do not share any information with each other. The action taken by other is not available to every agent.
- Decentralized setting with networked agents: All agents do not share complete information, but some agents interact with each other and share information.
Three representative information structures in MARL.