Meta Reinforcement Learning
An overview of the talk “Meta Reinforcement Learning DLRL talk” by Chelsea Finn, and “Meta Reinforcement Learning Blog”. In this talk, the author introduces about the concept of Meta Reinforcement Learning. All images and tables in this post are from their talk and blog.
Introduction
The key idea is an pursuit to enable systems to leverage previous experience in order to learn from little data. The goal is to explicitly learn priors from previous experience that lead to efficient downstream tasks. A meta-RL model is trained over a distribution of MDPs, and at test time, it is able to learn to solve a new task quickly. The goal of meta-RL is ambitious, taking one step further towards general algorithms.
Meta-RL Problem Formulation & Examples
The problem formulation is analogous to the meta-learning setting. However, instead, our inputs are the states , and outputs are the actions
. Our goal instead to learn the policy
that maps states to actions parameterized by
such that
.
In this scenario, the datasets are analogous to some transitions of the form
. Our goal is to learn a policy that maximizes reward. In conclusion, the goal of meta-RL is to leverage previous experience such as
(which could be
rollouts from
), and to predict the action for an unknown state
such that
.
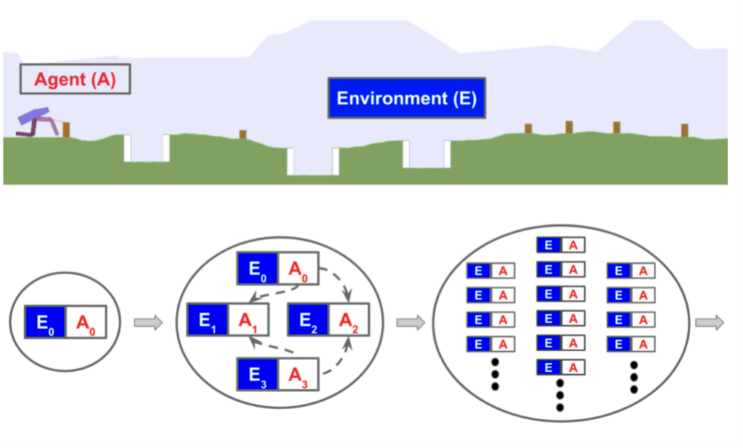
Usually the train and test tasks are different but drawn from the same family of problems; i.e., experiments in the papers included multi-armed bandit with different reward probabilities, mazes with different layouts, same robots but with different physical parameters in simulator, and many others. Let’s say we have a distribution of tasks, each formularized as an MDP (Markov Decision Process), . An MDP is determined by a 4-tuple,
. Note that a common state
and action space
are used above, so that a (stochastic) policy:
would get inputs compatible across different tasks. The test tasks are sampled from the same distribution
or slightly modified version.
Illustration of meta-RL, containing two optimization loops. The outer loop samples a new environment in every iteration and adjusts parameters that determine the agent’s behavior. In the inner loop, the agent interacts with the environment and optimizes for the maximal reward.
Connection to Contextual Policies
Contextual policy is a policy that is conditioned on some context . For example,
could be the position where you want to stack a block in, or maybe the direction that you want to walk in. In many ways, you can view this as a kind of contextual policies or kind of as a special case of these kinds of models. Where, the experience of the data is serving as the context to the policy.
Connections to contextual policies
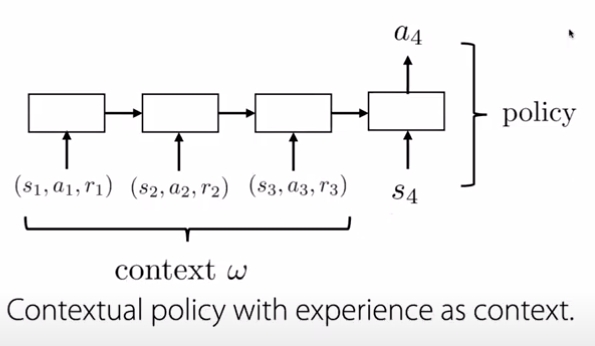
You could view meta-RL as contextual policies with data as context. In meta-RL, the rewards allow you to adapt to any task, even if that task is not a goal reaching task. In that way, these rewards are strict to generalization of goal-based tasks. Furthermore Contextual policies can be viewed as a 0-shot problem, where the goal is to generalize to new goals, rather than adapting to new ones.
Methods
There are two key research directions here, one is the design and optimization of , and the other is collecting appropriate data (learning to explore) or tasks for prior experience.
Black-Box / Context-Based models
The design of could be a RNN, an Attention-based network or Temporal Convolutional network. The overall goal is to predict an action for all aggregated states in the inputs.
General working of Reinforcement Learning
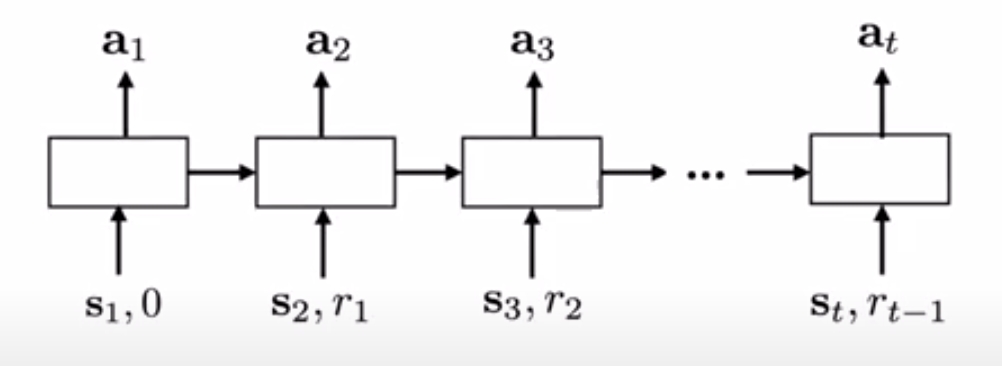
Note that, this takes as input the reward at previous timestep, which is important when we want to adapt to different reward functions. Another difference is that the hidden layers are not maintained across episodes, in order to facilitate easy adaptation to new tasks. These networks are quite general and highly expressive. Furthermore, there is higher flexibility as to how you want to approach the data. A downside to this method is that, the model is quite complex. Learning from complex tasks from scratch is quite difficult, and may require impractical amounts of data in order to adapt properly.
Optimization-Based models
Fine-tuning is the core of optimization-based models. We pre-train the model on a given data, and adapt to a novel dataset. This works quite well in both computer vision setting and natural language processing setting. However, this idea cannot be directly implemented in the few-shot setting. Suppose, you pre-train on ImageNet and then fine-tune on only a few examples, it’s likely to overfit for the small dataset. We need to explicity optimize for the few-shot case, where we perform few adaptations on the new task, and then optimize for those parameters on held out data.
Optimization-based models
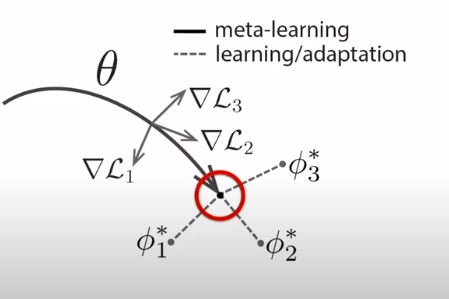
The idea is to reach an optima where fine-tuning to each task is easy, and close, as shown in the highlighted version above. These methods have an inductive bias of SGD built in. They are also model-agnostic, and could be integrated with any architecture. One issue is that RL gradients (policy gradients, or Bellman error) are often not very informative.
Learning to Explore
This section discusses the important problem: “How should we collect ?”
Solution #0:
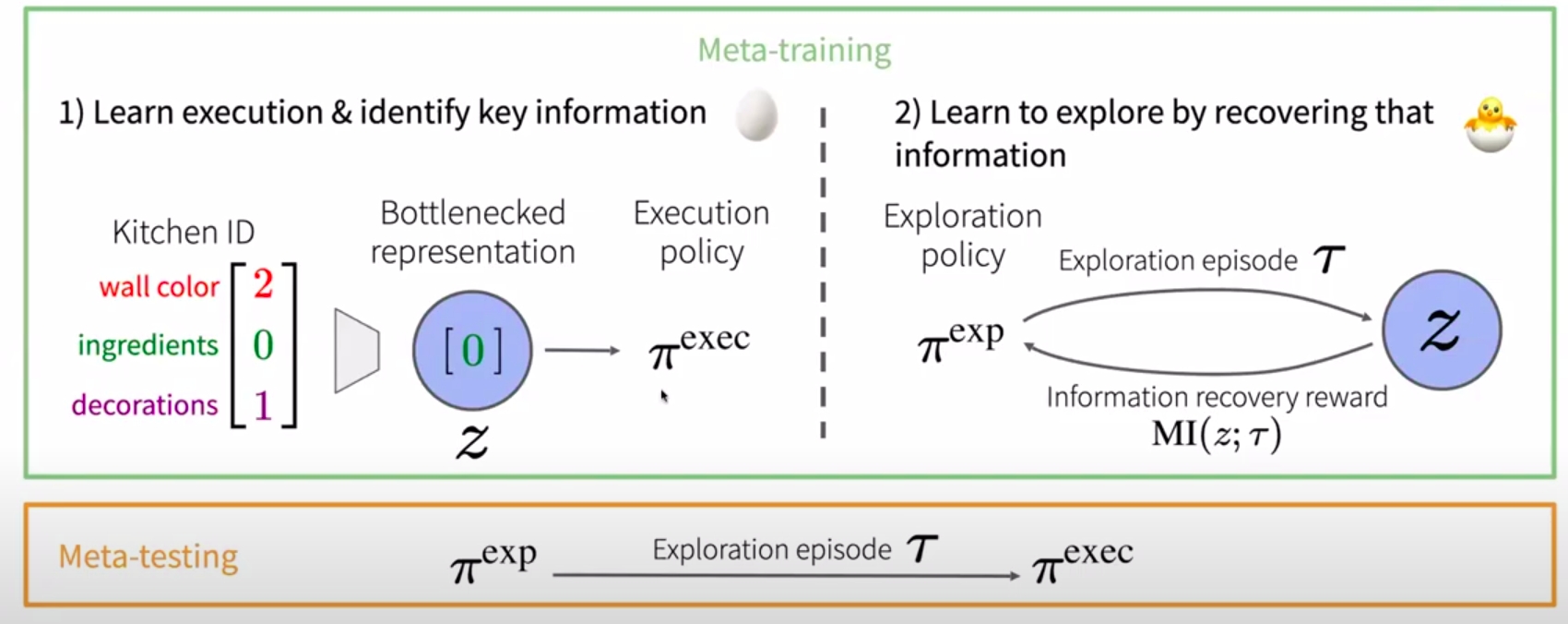
The first solution is to optimize for Exploration & Execution End-to-End w.r.t. reward. The approach is quite simple, and would lead to optimal strategy in principle. However, the downside is that the optimization approach is exceedingly challenging when exploration is difficult. An example of hard exploration meta-rl problem is to learn cooking tasks in previous kitchens. The goal is to quickly learn tasks in a new kitchen. It is quite difficult for the model to understand where all the utensils are, what the environment is, etc. During meta-testing, there are two episodes: one exploration episode to understand where all the equipments are, one for execution.
The reason end-to-end training is hard because we have a chicken and egg problem. We need to do two things, learn how to find ingredients (exploration), and we need to learn how to cook (execution). And if we have a bad exploration policy (cannot find ingredients), and hence, leads to bad execution (cannot learn to cook). Furthermore, if we have a bad execution policy (cannot cook), we would have low reward for any exploration (simply because you cannot cook).
Solution #1:
Another solution is to leverage alternative exploration strategies.
- Use posterior sampling: One first learns a distribution over latent task variable
if we have not seen any data, or
if we have seen some data. We also learn the corresponding task policies
for that task. We then sample
from current posterior and sample from policy
Posterior sampling
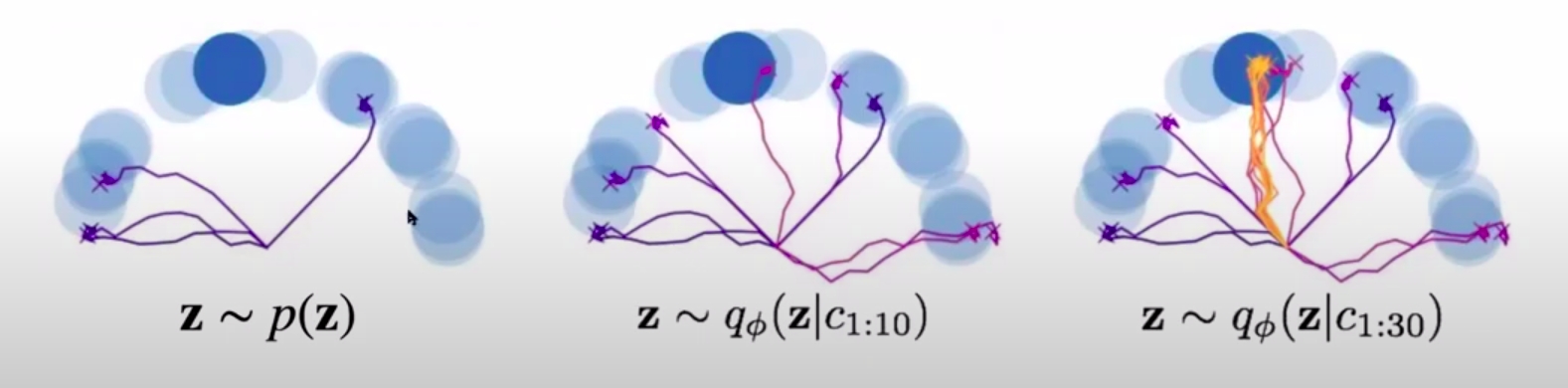
This strategy might not be optimal. Suppose the goal is far away, and there is a sign indicating the path to the sign. The posterior sampling model would not look at the sign, and simply sample goals. The optimal strategy would be to look at the sign.
- Another approach is to use intrinsic rewards
- Another sample is to predict task dynamics and rewards. In this case, we train the model
. We then collect
so that the model is accurate. This may not be optimal where we have a lot of distractors or high dimensional state dynamics.
Many of these methods are easy to optimize, and based on principled strategies. However, these might be suboptimal by arbitrarily large amount in some environments.
Solution #2:
The last solution is to decouple by acquiring representation of task relevant information. This can be theoretically proved to be similar to Solution #0.
Decoupled Reward-free ExplorAtion and Execution in Meta-reinforcement learning(DREAM)
Main Differences from RL
The overall configure of meta-RL is very similar to an ordinary RL algorithm, except that the last reward and the last action
are also invorporated into the policy observation in addition to the current state
.
- In RL:
a distribution over
.
- In meta-RL:
a distribution over
The intention of this design is to feed history to the model so that the policy can internalize the dynamics between states, rewards, and actions in the current MDP and adjust its strategy accordingly. Meta-RL generally implement an LSTM policy and the LSTM’s hidden states serve as a memory for tracking characteristics of the trajectories. Becayse the policy is recurrent, there is no need to feed the last state as inputs explicitly.
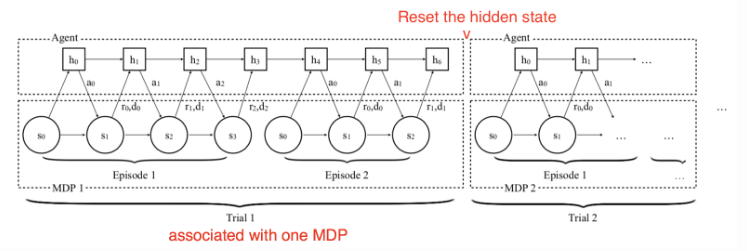
The training procedure works as follows:
- Sample a new MDP,
;
- Reset the hidden state of the model;
- Collect multiple trajectories and update the model weights;
- Repeat from step 1.
, Illustration of the procedure of the model interacting with a series of MDPs in training time in RL^2 model.
Key Components
There are three key components in Meta-RL:
- A model with Memory: A recurrent neural network maintains a hidden state. Thus, it could acquire and memorize the knowledge about the current task by updating the hidden state during rollouts. Without memory, meta-RL would not work.
- Meta-learning Algorithm: A meta-learning algorithm refers to how we can update the model weights to optimize for the purpose of solving an unseen task fast at test time. In both Meta-RL and RL^2 papers, the meta-learning algorithm is the ordinary gradient descent update of LSTM with hidden state reset between a switch of MDPs.
- A Distribution of MDPs: While the agent is exposed to a variety of environments and tasks during training, it has to learn how to adapt to different MDPs.
The Meta-RL approach involves three pillars: (1) meta-learning architectures, (2) meta-learning algorithms, and (3) automatically generated environments for effective learning.
Meta-Learning Algorithms for Meta-RL
Optimization Model Weights for Meta-Learning
Both MAML and Reptile are methods on updating model parameters in order to achieve good generalization performance on new tasks.
Meta-learning Hyperparameters
The return function in an RL problem, or
, involves a few hyperparameters that are often set heuristically, like the discount factor
and the bootstrapping parameters
. Meta-gradient RL considers them as meta-parameters,
, that can be tuned and learned online while an agent is interacting with the environment. Therefore, the return becomes a function of
and dynamically adapts itself to a specific task over time.
\
During training, we would like to update the policy parameters with gradients as a function of all the information in hand, , where
are the current model weights,
is a sequence of trajectories, and
are the meta-parameters.
Meanwhile, let’s say we have a meta-objective function as a performance measure. The training process follows the principle of online cross-validation, using a sequence of consecutive experiences:
- Starting with parameter
, the policy
is updated on the first batch of samples
, resulting in
.
- Then we continue running the policy
to collect a new set of experiences
, just following
with a fixed meta-parameter
.
- The gradient of meta-objective
is used to update
The meta-gradient RL algorithm simplifies the computation by setting the secondary gradient term to zero, this choice prefers the immediate effect of the meta-parameters on the parameters
. Eventually, we get:
Experiments in the paper adopted the meta-objective function same as algorithm, minimizing the error between the approximated value function
and
-return:
\
Meta-learning Loss function
In policy gradient algorithms, the expected total reward is maximized by updating the policy parameters in the direction of estimated gradient:
where the candidates for include the trajectory return
, the Q value
, or the advantage value
. The corresponding surrogate loss function for the policy gradient can be reverse-engineered:
This loss function is a measure over a history of trajectories, (). Evolved Policy Gradient takes a step further by defining the policy gradient loss function as a temporal convolution (1-D convolution) over the agent’s past experience,
. The parameters
of the loss function network are evolved in a way that an agent can achieve higher returns.
Similar to many meta-learning algorithms, EPG has two optimization loops:
- In the internal loop, an agent learns to improve its policy
- In the outer loop, the model updates the parameters
of the loss function
. Because there is no explicit way to write down a differentiable equation between the return and the loss, EPG turned to Evolutionary Strategies (ES).
A general idea is to train a population of agents, each of them is trained with the loss function
parameterized with
added with a small gaussian noise
of standard deviation
, During the inner loop’s training, EPG tracks a history of experience and updates the policy parameters according to the loss function
for each agent:
where is the learning rate of the inner loop and
is a sequence of M transition steps up to the current time step
.
Once the inner loop policy is mature enough, the policy is evaluated by the mean return
over multiple randomly sampled trajectories. Eventually, we are able to estimate the gradient of
according to NES numerically. While repeating this process, both parameters
and the loss function weights
are being updated simultaneously to achieve higher returns.
where is the learning rate of the outer loop.
In practice, the loss is bootstrapped with an ordinary policy gradient (such as REINFORCE or PPO) surrogate loss
,
. The weight
is annealing from 1 to 0 gradually during traning. At test time, the loss function parameter
stays fixed and the loss value is computed over a history of experience to update the policy parameters
.
Meta-learning Exploration Strategies
The exploitation vs exploration dilemma is a critical problem in RL. Common ways to do exploration include -greedy, random noise on actions, or stochastic policy with built-in randomness on the action space.
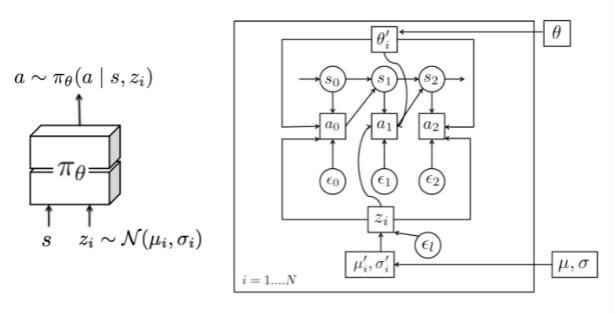
MAESN is an algorithm to learn structured action noise from prior experience for better and more effective exploration. Simply adding random noise on actions cannot capture task-dependent or time-correlated exploration strategies. MAESN changes the policy to condition on a per-task random variable , for i-th task
, so we would have a policy
. The latent variable
is sampled once and fixed during one episode. Intuitively, the latent variable determines one type of behavior (or skills) that should be explored more at the beginning of a rollout and the agent would adjust its actions accordingly. Both the policy parameters and latent space are optimized to maximize the total task rewards. In the meantime, the policy learns to make use of the latent variables for exploration.
In addition, the loss function includes the KL divergence between the learned latent variable and a unit Gaussian prior, . On one hand, it restricts the learned latent space not too far from a common prior. On the other hand, it creates the variational evidence lower bound (ELBO) for the reward function. Interestingly, the paper found that
for each task are usually close to the prior at convergence.
The policy is conditioned on a latent variable variable that is sampled once every episode. Each task has different hyperparameters for the latent variable distribution, (\mu_i, \sigma_i) and they are optimized in the outer loop.
Episodic Control
A major criticism of RL is on its sample inefficiency. A large number of samples and small learning steps are required for incremental parameter adjustment in RL in order to maximize generalization and avoid catastrophic forgetting of earlier learning.
An episodic memory keeps explicit records of past events and uses these records directly as point of reference for making new decisions (just like metric-based meta-learning).
In MFEC(Model-Free episodic control), the memory is modeled as a big table, storing the action pair as key and the corresponding Q-value
as value. When receiving a new observation
, the Q-value is estimated in an non-parametric way as the average Q-value of top
most similar samples:
where are the top
states with smallest distances to the state
. Then the action yields the highest estimated Q value is selected. Then the memory is updated according to the return received at
:
A tabular RL method, MFEC suffers from large memory consumption and a lack of ways to generalize among similar states. The fisrt one can be fixed with an LRU cache. Inspired by metric-based meta-learning, especially Matching Networks, the generalization problem is improved in a follow-up algorithm, NEC (Neural Episodic Control).
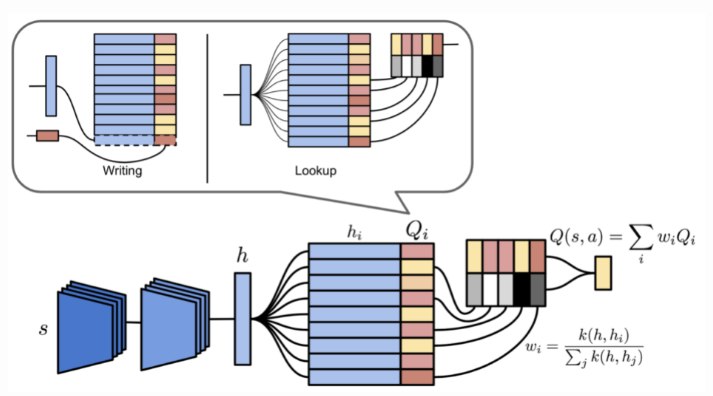
The episodic memory in NEC is Differentiable Neural Dictionary (DND), where the key is a convolutional embedding vector of input image pixels and the value stores estimated Q value. Giving an inquiry key, the output is a weighted sum of values of top similar keys, where the weight is a normalized kernel measure between the query key and selected key in the dictionary. This sounds like a hard attention mechanism.
Illustrations of episodic memory module in NEC an two operations on a differentiable neural dictionary.
Further, Episodic LSTM enhances the basic LSTM achitecture with a DND episodic memory, which stores task context embeddings as keys and the LSTM cell states as values. The stored hidden states are retrieved and added directly to the current cell state through the same gating mechanism within LSTM:
Illustrations of episodic LSTM architecture. The additional structure of episodic memory is in bold.
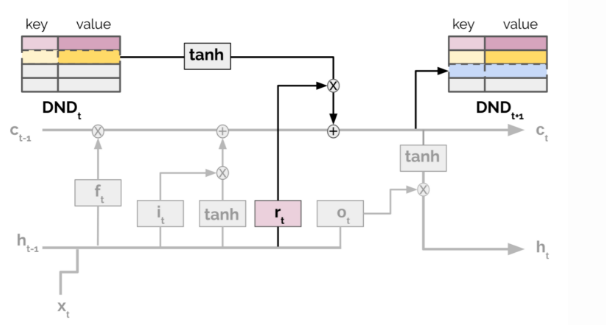
The architecture provides a shortcut to the prior experience through context-based retrieval. Meanwhile, explicitly saving the task-dependent experience in an external memory avoids forgetting. In the paper, all experiments have manually designed context vectors. How to construct an effective and efficient format of task context embeddings for more free-formed tasks would be an interesting topic.
Overall, the capacity of episodic control is limited by the complexity of the environment. It is very rare for an agent to repeatedly visit exactly the same states in a real-world task, so properly encoding the states is critical. The learned embedding space compresses the observational data into a lower dimensional space, and, in the meantime, two states being close in this space are expected to demand similar strategies.
Training Task Acquisition
Among the three key components, how to design a proper distribution of tasks is the less studied and probably the most specific one to meta-RL itself. As described earlier, each task is a MDP: . We can build a distribution of MDPs by modifying:
- The reward configuration: Among different tasks, the same behavior might get rewarded differently according to
.
- Or, the environment: The transition function
can be reshaped by initializing the environment with varying shifts between states.
Task Generation by Domain Randomization
Randomizing parameters in a simulator is an easy way to obtain tasks with modified transition functions.
Evolutionary Algorithm on Environment Generation
Evolutionary algorithm is a gradient-free heuristic-based optimization method, inspired by natural selection. A population of solutions follows a loop of evaluation, selection, reproduction, and mutation. Every good solutions survive and thus get selected.
POET, a framework based on the evolutionary algorithm, attempts to generate tasks while the problems themselves are being solved. The implementation of POET is only specifically designed for a simple 2D bipedal walker environment but points out an interesting direction. It is noteworthy that the everloutionary algorithm has had some compelling applications in Deep Learning.
The 2D bipedal walking environment is evolving: from a simple flat surface to a much more difficult trail with potential gaps, stumps and rough terrains. POET pairs the generation of environmental challenges and optimization of agents together so as to (a) select agents that can resolve current challenges and (b) evolve environments to be solvable. The algorithm maintains a list of environment agent pairs and repeats the following:
- Mutation: Generate new environments from currently active environments. Note that here types of mutation operations are created just for bipedal walker and a new environment would demand a new set of configurations.
- Optimization: Train paired agents within their respective environments.
- Selection: Periodically attempt to transfer current agents from one environment to another. Copy and update the best performing agent for every environment. The intuition is that skills learned in one environment might be helpful for a different environment.
The procedure above is quite similar to PBT, but PBT mutates and evolves hyperparameters instead. To some extent, POET is doing domain randomization, as all gaps, stumps and terrain roughness are controlled by some randomization probability parameters. Different from DR, the agents are not exposed to a fully randomized difficult environment all at once, but instead they are learning gradually with a curriculum configured by the evolutionary algorithm.
An example bipedal walking environment(top) and an overview of POET(bottom).
Learning with Random Rewards
An MDP without a reward function is known as Controlled Markov Process (CMP). Given a predifined CMP,
, we can acquire a variety of tasks by generating a collection of reward functions
that encourage the training of an effective meta-learning policy.
There are two unsupervised approaches for growing the task distribution in the context of CMP. Assuming there is an underlying latent variable associated with every task, it parameterizes/determines a reward function:
, where a “discriminator” function
is used to extract the latent variables from the state. There are two ways to create this discriminator function:
- Sample random weights
of the discriminator,
.
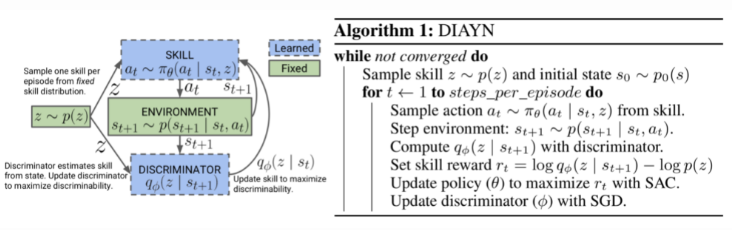
- Learn a discriminator function to encourage diversity-driven exploration. This method was introduced in a paper called “DIAYN”.
DIAYN (Diversity is all you need), is a framework to encourage a policy to learn useful skills without a reward function. It explicitly models the latent variables as a skill embedding, and makes the policy conditioned on this latent variable, in addition to state:
. The design of DIAYN is motivated by a few hypotheses:
- Skills should be diverse and lead to visitations of different states. This helps maximize the mutual information between states and skills,
.
- Skills should be distinguished by states, not actions. This helps minimize the mutual information between actions and skills, conditioned on states
.
The objective function to maximize is as follows, where the policy entropy is also added to encourage diversity:
\
\
\
\
The above equation can infer skills from state and
is diverse. Furthermore, according to Jensen’s inequality; “pseudo-reward” is represented in red.
Here, is mutual information and
is entropy measure. We cannot integrate all states to compute
, so approximate it with
- that is the diversity-driven discriminator function.
Once the discriminator is learned, sampling a new MDP for training is straight-forward: First, we sample a latent variable, and construct a reward function
. Pairing the reward function with a predefined CMP creates a new MDP.
DIAYN Algorithm.
Challenges & Latest Developments
Some of the open-ended problems include:
- Adapting to entirely new tasks or dataset - Meta-World benchmark as a starting point?
- Robustness to out of distribution tasks
- Where do the tasks even come from
- Need better RL algorithms