One-Shot Free-View Neural Talking-head Synthesis for Video Conferencing
An overview of the paper “One-Shot Free-View Neural Talking-head Synthesis for Video Conferencing”. The authors propose a model that can re-create a talking-head video using only a single source image and a sequence of unsupervisedly-learned 4D keypoints, representing motions in the video. The model is 10x more efficient than the H.264 standard. All images and tables in this post are from their paper.
Introduction
The authors propose a neural talking-head video synthesis model and demonstrate its applications to video conferencing. The model learns to synthesize a talking-head video using a source image containing the target person’s appearance and a driving video that dictates the motion in the output. The motion is encoded based on a novel keypoint representation, where the identity-specific and motion related information is decomposed unsupervisedly. In this work, the authors use a graphical model which is local free view. This allows to synthesize the talking-head from other viewpoints and addresses the fixed viewpoint limitation and achieves local free-view synthesis. The contribution from this work are 3-fold:
- Contribution 1:A novel one-shot neural talking-head synthesis approach, which achieves better visual quality than state-of-the art methods on the benchmark datasets.
- Contribution 2:Local free-view control of the output video, without the need for a 3D graphics model. The model allows changing the viewpoint of the talking-head during synthesis.
- Contribution 3:Reduction in bandwidth for video-streaming by almost 10x.
Overview of proposed approach.
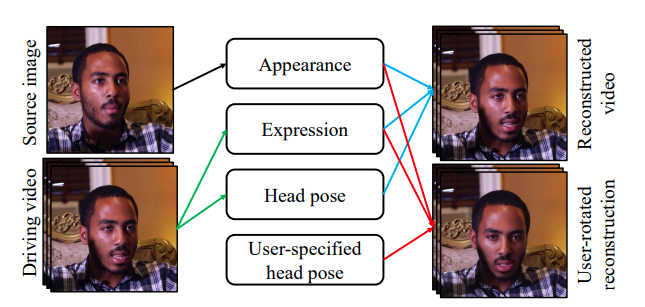
People’s faces have an inherent structure- from the shape to the relative arrangement of different parts such as eyes, nose, mouth, etc. This allows us to use keypoints and associated metadata for efficient compression, an order of magnitude better than traditional codecs. The model does not guarantee pixel aligned output videos; however, it faithfully models facial movements and emotions. The proposed method can be divided into three major steps:
- Source image feature extraction
- Driving video feature extraction
- Video generation
Source image feature extraction
Different features extracted from the source image.
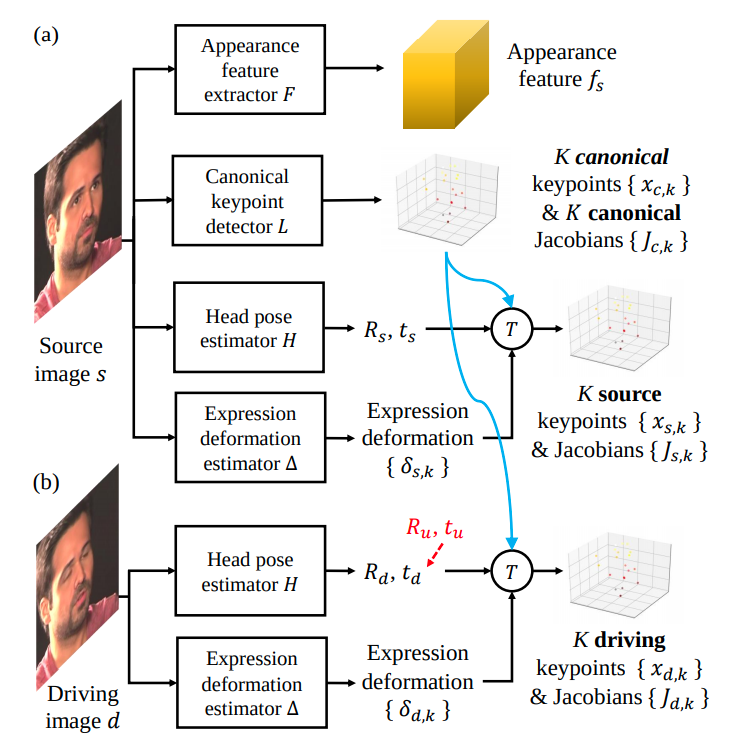
-
3D appearance feature extraction (
): Using a neural network
is mapped to a 3D appearance feature volume
.
-
3D canonical keypoint extraction (
): Using a canonical 3D keypoint detection network
canonical 3D keypoints
and their Jacobians
are extracted from
-
Head Pose (
) and Expression Extraction (
): A pose estimation network
and a translation vector
. The rotation matrix in practice is composed of three matrices. Expression deformation estimation network
. The same architecture is used to extract motion-related information from the driving video.
Driving Video Feature Extraction
Different features extracted from the driving video.
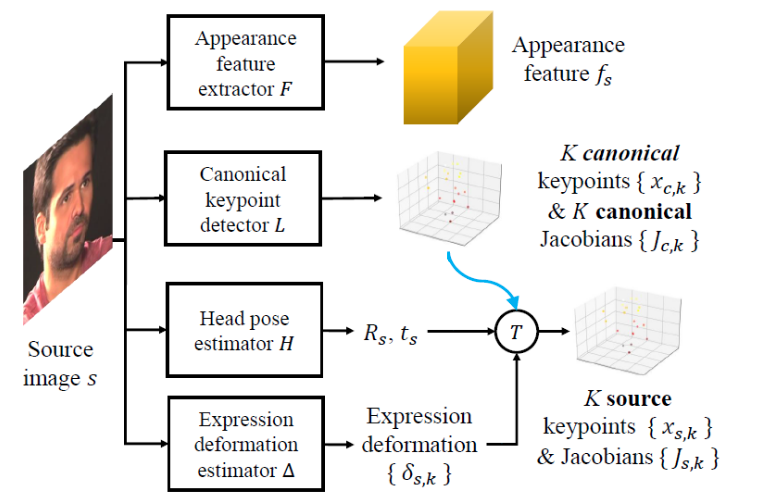
The driving video is used to extract motion-related information. To this end, head pose estimation network and expression deformation estimator network
is used. In video conferencing, we can change a person’s head pose in the video stream freely despite the original view angle.
Video Generation
Video synthesis pipeline.
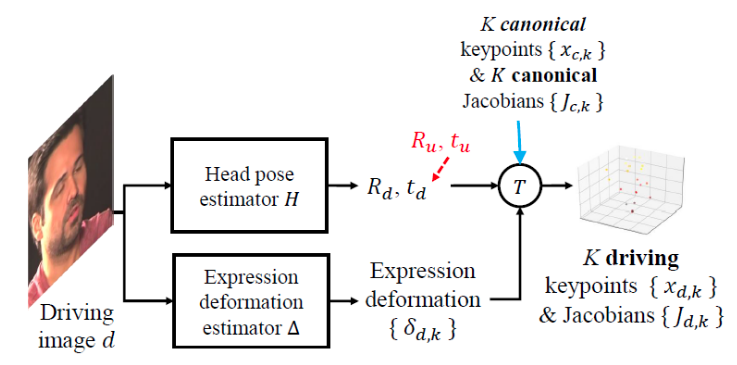
To summarize so far, we have source image and driving video
. The task is to generate output video
such that it has the identity-specific information from
and motion-specific information from
. To obtain identity-specific information different neural networks are used and the same goes for motion-specific information. These pieces of information are used to obtain
3D keypoints and Jacobians for both
and
.
These keypoints and Jacobians are then used to warp the source appearance feature
extracted from
from which they generate the final output image using a generator network
.
Training the models
For each video, two frames were sampled, one as source image, and other frame from the driving video. The networks are trained together by minimizing the following loss:
Here,
- Perpetual Loss (
): Perpetual loss is used in image reconstruction tasks. Derived from the VGG network layer.
- GAN Loss(
): Here, they used patch GAN implementation along with hinge loss.
- Equivalence Loss (
): This loss ensures the consistency of the estimated keypoints.
- Key prior Loss (
): This loss encourages the estimated image-specific keypoints to spread out across the face region, instead of crouding around a small neighborhood.
- Head Pose Loss(
):
distance is computed between the estimated head pose and the one predicted by a pre-trained estimator. This approximation is as good as the pre-trained model head pose estimator.
- Deformation prior Loss(
): This loss is simply given as
.
Conclusion
The results of this research are really quite promising. The techniques we talked about here resulted in 10X bandwidth reduction, and the video quality is high considering the reduction. Models like this could make it possible to demonetize access to viedo conferencing and reduce strain on networks, especially in residential and rural areas where bandwidth is already harder to come by.