Reinforcement Learning
An overview of the topic “A (Long) Peek into Reinforcement Learning”. Say, we have an agent in an unknown environment and this agent can obtain some rewards by interacting with the environment. The agent ought to take actions so as to maximize cumulative rewards. The goal of Reinforcement Learning (RL) is to learn a good strategy for the agent from experimental trials and relatively simple feedback received. With the optimal strategy, the agent is capable to actively adapt to the environment to maximize future rewards.
An agent interacts with the environment, trying to take smart actions to maximize cumulative rewards.
Background
The agent is acting in an environment. How the environment reacts to certain actions is defined by a model which we may or may not know. The agent can stay in one of the many states () of the environment, and choose to take one of the many actions (
) to switch from one state to another. Which state the agent will arrive in is decided by transition probabilities between states (
). Once an action is taken, the environment delivers a reward (
) as feedback.
The model defines the reward functions and transition probabilities. We may or may not know how the model works and this differentiate two circumstances:
- Know the model: planning with perfect information; do model-based RL. When we fully know the environment, we can find the optimal solution by Dynamic Programming.
- Do not know the model: learning with incomplete information; do model-free RL or try to learn the model explicitly as part of the algorithm. Most of the following content serves the scenarios when the model is unknown.
The agent’s policy () provides the guidelines on what is the optimal action to take in a certain state with the goal to maximize total rewards. Each state is associated with a value function
predicting the expected amount of future rewards we are able to receive in this state by acting the corresponding policy. In other words, the value function quantifies how good a state is. Both policy and value functions are what we try to learn in reinforcement learning.
Summary of approaches in RL based on whether we want to model the value, policy, or the environment.
The interaction between the agent and the environment involves a sequence of actions and observed rewards in time, . During the process, the agent accumulates the knowledge about the environment, learns the optimal policy, and makes decisions on which action to take next so as to efficiently learn the best policy. Let’s label the state, action, and reward at time step
as
,
, and
, respectively. Thus, the interaction sequence is fully described by one episode (also known as “trial” or “trajectory”) and the sequence ends at the terminal state
:
Some important terms in RL algorithms involve:
- Model-based: Rely on the model of the environment; either the model is known or the algorithm learns it explicitly.
- Model-free: No dependency on the model during learning.
- On-policy: Use the deterministic outcomes or samples from the target policy to train the algorithm.
- Off-policy: Training on a distribution of transitions or episodes produced by a different behavior policy rather than that produced by the target policy.
Model: Transition and Reward
The model is a descriptor of the environment. With the model, we can learn or infer how the environment would interact with and provide feedback to the agent. The model has two major parts, transition prbability function , and reward function
.
Suppose, we are in state , we decide to take action
to arrive in the next state
and obtain reward
. This is known as one transition step represented by a tuple
.
The transition function records the probability of transitioning from state
to
after taking action
while obtaining reward
. We use
as a symbol of probability.
Thus, the state-transition function can be defined as a function of :
Similarly, the reward function predicts the next reward triggered by a given action:
Policy
Policy is defined as the agent’s behavior function , and tells us which action to take in state
. It is a mapping from state
to action
and can either be deterministic or stochastic.
- Deterministic:
- Stochastic:
Value function
Value function measures the goodness of a state, or how rewarding a state or action is by predicting future reward. The future reward is also known as return, and is the total sum of discounted rewards going forward.
The discounting factor penalize the rewards in the future for few reasons:
- The future rewards may have higher uncertainty.
- The future rewards do not provide immediate benefits.
- Discounting provides mathematical convenieve; we can make approximations .
- We do not need to worry about the infinite loops in state transition graph.
The state-value of a state is the expected return if we are in this state at time
,
:
Similarly, we define the action-value (“Q-value”) of a state-action pair as:
Additionally, since we follow the target policy , we can make use of the probility distribution over possible actions and the Q-values to recover the state-value:
The difference between action-value and state-value is the action advantage function (“A-value”):
This can be thought of as the advantage of selecting an action in a given state
compared to all other actions available to you.
Optimal Value and Policy
The optimal value function produces the maximum return:
The optimal policy achieves optimal value functions:
Markov Decision Processes
In formal terms, almost all RL problems can be framed as Markov Decision Processses (MDPs). All states in MDP have “Markov” property, referring to the fact that the future only depends on the current state, not the history:
In other words, the future and the past are conditionally independent given the present, as the current state encapsulates all the statistics we need to decide the future.
The agent-environment interaction in a Markov decision process.
A Markov decision process consists of five elements , where the symbols have the same meanings as discussed in previous sections. Note that, in an unknown environment, we do not have perfect knowledge about
and
.
Bellman Equations
Bellman equations refer to the set of equations that decompose the value function into the immediate reward plus the discounted future values.
Similarly, for Q-value,
Bellman Expectation Equations
The recursive update process can be further decomposed to be equations built on both state-value functions. As we go further in future action steps, we extend and
alternatively by following the policy
.
Illustration of how Bellman expectation equations update state-value and action-value functions.
If we are interested in the optimal values rather than computing the expectation following a policy, we could jump right into the maximum returns during the alternative updates without using a policy. If we have complete information of the environment, this turns into a planning problem, solvable by DP. Unfortunately, in most scenarios, we do not know or
, so we cannot solve MDPs by directly applying Bellmen equations, but it lays the theoretical foundation for many RL algorithms.
Common Approaches
In this section, we discuss some of the common approaches and classical algorithms used for solving RL problems.
Dynamic Programming
When the model is fully known, following Bellman equations, we can use DP to iteratively evaluate the value functions and improve policy.
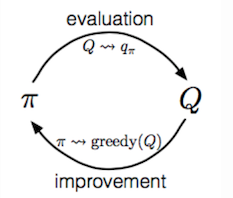
Policy Evaluation
Policy evaluation is to compute the state-value for a given policy
:
Policy Improvement
Based on the value functions, Policy improvement generates a better policy by acting greedily.
Policy iteration
The Generalized Policy Iteration (GPI) algorithm refers to an iterative procedure to improve the policy when combining policy evaluation and improvement.
In GPI, the value function is approximated repeatedly to be closer to the true value of the current policy, and in meantime, the policy is improved repeatedly to approach optimality. Say, we have a policy and then generate an improved version
by greedily taking actions,
.
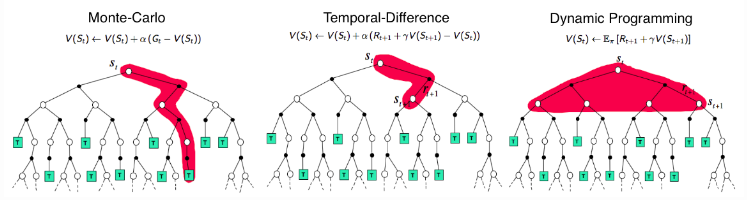
Monte-Carlo Methods
Monte-Carlo (MC methods use a simple idea: It learns from episodes of raw experience without modeling the environmental dynamics and computes the observed mean return as an approximation of the expected return. To compute the empirical return , MC methods need to learn from complete episodes:
to compute
and all episodes must eventually terminate.
THe empirical mean return for state
is:
where, is a binary indicator function. We may count the visit of state
every time so that there could exist multiple visits of one state in one episode, or only count it the first time we encounter a state in one episode. This way of approximation can easily be extended to action-value functions by counting
pair.
Illustration of MC approach.
To learn the optimal policy by MC, we iterate it by following a similar idea to GPI.
- We improve the policy greedily with respect to the current value function:
.
- Generate a new episode with the new policy
- Estimate
using the new episode:
Temporal-Difference Learning
Similar to Monte-Carlo methods, Temporal Difference (TD) learning is model-free and learns from episodes of experience. However, TD learning can learn from incomplete episodes and hence we don’t need to track the episode up to termination.
Bootstrapping
TD learning methods update targets with regard to existing estimates rather than exclusively relying on actual rewards and complete returns as in MC methods. This approach is known as bootstrapping.
Value Estimation
The key idea in TD learning is to update the value function towards an estimated return
(known as “TD target”). To what extent we want to update the value function is controlled by the learning rate hyperparameter
:
\
\
Similarly, for the action-value estimation:
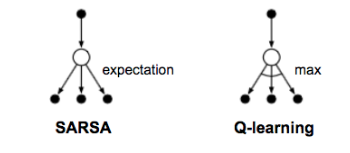
SARSA: On-Policy TD control
“SARSA” refers to the procedure of updating Q-value by following a sequence of . The idea follows the same route of GPI. A brief explanation of the algorithm is as follows:
- Initialize
.
- Start with
and choose action
, where
-greedy is commonly applied.
- At time
, after applying action
, we observe reward
and get into the next state
.
- Then pict the next action in the same way.
- Update the Q-value function:
- Set
and repeat from step 3.
In each step of SARSA, we need to choose the next action according to the current policy.
Q-Learning: Off-policy TD control
The development of Q-learning is a big breakout in the early days of Reinforcement Learning. Within one episode, it works as follows:
- Initialize
- Start with
- At time step
and
- After applying action
- Update the Q-value function:
- Set
The key difference from SARSA is that Q-learning does not follow the current policy to pick the second action . It estimates
out of the best Q values, but which action (denoted as
) leads to this maximal Q does not matter. Instead, in the next step Q-learning may not follow
.
The backup diagrams for Q-learning and SARSA.
Deep Q-Network
Combining TD and MC Learning
In the previous section on value estimation in TD learning, we only trace one step further down the action chain when calculating the TD target. One can easily extend it to take multiple steps to estimate the return.
Let’s label the estimated return followin steps as
,
, then:

The generalized n-step TD learning still has the same form of value function:
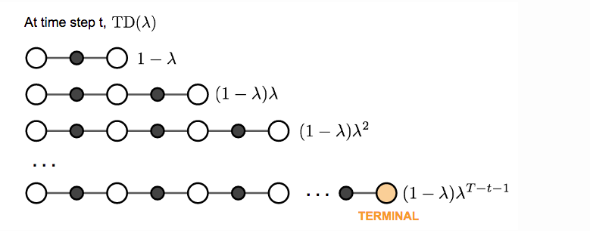
We are free to pick any in TD learning as we like. Now, the question becomes what is the best
? Which
gives us the best return approximation? A common yet smart solution is to apply a weighted sum of all possible n-step TD targets rather than pick the best
. The weight decay by a factor
with n,
; the intuition is similar to why we want to discount future rewards when computing tje return: the more future we look into, the less confident we would be. To make all the weight (
) sum up to 1, we multiply every weight by (
).
The weighted sum of many n-step returns is called -return
. TD learning that adopts
-return for value updating is labeled as TD(
). The original version introduced above is equivalent to TD(0).
Comparison of backup diagrams of Monte-Carlo, Temporal-Difference learning, and Dynamic Programming for state value functions.
Policy Gradient
All the methods we have introduced above aim to learn the state/action function and then to select actions accordingly. Policy gradient methods instead learn the policy directly with a parameterized function with respect to ,
. Let’s define the reward function (opposite of loss function) as the expected return and train the algorithm with the goal to maximize the reward function. In discrete space:
where is the initial starting state.
Or in continuous space:
where is stationary distribution of Markov chain for
. Using gradient ascent, we can find the best
that produces the highest return. It is natural to expect policy-based methods are more useful in continuous space, because there is an infinite number of actions and/or states to estimate the values for in continuous space and hence value-based approaches are computationally much more expensive.
Policy Gradient Theorem
Computing the gradient numerically can be done perturbing by a small amount
in the k-th dimension. It works wven when
is not differentiable, but unsurprisingly very slow.
Or analytically,
Actually we have nice theoretical support for replacing with
:
This result is named “Policy Gradient Theorem” which lays the theoretical foundation for various policy gradient algorithms:
Reinforce
REINFORCE, also known as Monte-Carlo policy gradient, relies on , an estimated return by MC methods using episode samples, to update the policy parameter
.
A commonly used variation of REINFORCE is to subtract a baseline value from the return to reduce the variance of gradient estimation while keeping the bias unchanged. For example, a common baseline is state-value, and if applied, we would use
in the gradient ascent update.
- Initialize
at random.
- Generate one episode:
- For
:
- Estimate the return
since the time step
.
- Estimate the return
Actor-Critic
If the value function is learned in addition to the policy, we would get Actor-Critic algorithm.
- Critic: updates value function parameters
and depending on the algorithm it could be action-value
or state value
.
-
Actor: updates policy parameters
.
- Initialize
,
.
- For
- Sample reward
and next state
.
- Then sample the next action
.
- Update policy parameters:
.
- Compute the correction for action-value at time t:
, and use it to update value function parameters:
.
- Update
and
.
- Sample reward
and
are two learning rates for policy and value function parameter updates, respectively.
A3C
Asynchronous Advantage Actor Critic, short for A3C is a classic policy gradient method with the special focus on parallel training.
In A3C, the critics learn the state-value function, , while multiple actors are trained in parallel and get synced with global parameters from time to time. Hence, A3C is good for parallel training by default.
The loss function for state-value is to minimize the mean squared error, and we use gradient descent to find the optimal
. This state-value function is used as the baseline in the policy gradient update.
Outline of the A3C Algorithm.

A3C enables the parallelism in multiple agent training. The gradient accumulation step (6.2) can be considered as a reformation of minibatch-based stochastic gradient update: the values of w or θ get corrected by a little bit in the direction of each training thread independently.
Evolution Strategies
Evolution Strategies(ES) is a type of model-agnostic optimization approach. It learns the optimal solution by imitating Darwin’s theory of the evolution of species by natural selection. Two prerequisites for applying ES: (1) our solutions can freely interact with the encironment and see whether they can sove the problem; (2) we are able to compute a fitness score of how good each solution is. We don’t have to know the environment configuration to solve the problem.
Say, we start with a population of random solutions. All of them are capable of interacting with the environment and only candidates with high fitness scores can survive (only the fittest can survive in a competition for limited resources). A new generation is then created by recombining the settings (gene mutation) of high-fitness survivors. This process is repeated until the new solutions are good enough.
Very different from the popular MDP-based approaches as what we have introduced above, ES claims to learn the policy parameter without value approximation. Let’s assume the distribution over the parameter
is an isotropic multivariate Gaussian with mean
and fixed covariance
. The gradient of
is calculated:
We can rewrite this formula in terms of a “mean” parameter (different from the
above; this
is the base gene for durther information),
and therefore
.
controls how much Gaussian noises should be added to create mutation:
ES, as a black-box optimization algorithm, is another approach to RL problems. It has few good characteristics:
- ES is fast and easy to train;
- ES does not need value function approximation;
- ES does not perform gradient back-propagation;
- ES is invariant to delayed or long-term rewards;
- ES is highly parallelizable with very little data communication.
Known Problems
Exploration-Exploitation Dilemma
When the RL problem faces an unknown environment, this issue is especially key to finding a good solution: without enough exploration, we cannot learn the environment well enough; without enough exploitation, we cannot complete our reward optimization task.
Different RL algorithms balance between exploration and exploitation in different ways. In MC methods, Q-learning or many on-policy algorithms, the exploration is commonly implemented by -greedy; In ES, the exploration is captured by the policy parameter perturbation.
Deadly Triad Issue
We do seek the efficiency and flexibility of TD methods that involve bootstrapping. However, when off-policy, nonlinear function approximation, and bootstrapping are combined to one RL algorithm, the training could be unstable and hard to converge. This issue is known as the deadly triad. Many architectures using deep learning models were proposed to resolve the problem, including DQN to stabilize the training with experience replay and occasionally frozen target network.
Case Study: AlphaGO Zero
The game of Go has been an extremely hard problem in the field of AI. AlphaGo and AlphaGo Zero are two programs developed by a team at DeepMind. Both involve deep CNN and Monte Carlo Tree Search (MCTS), and both have been approved to achieve the level of professional human Go players. Different from AlphaGo that relied on supervised learning from expert human moves, AlphaGo Zero used only reinforcement learning and self-play without human knowledge beyond basic rules.
The board of Go. Two players play black and white stones alternatively on the vacant intersections of a board with 19 x 19 lines. A group of stones must have at least one open point (an intersection, called a “liberty”) to remain on the board and must have at least two or more enclosed liberties (called “eyes”) to stay “alive”. No stone shall repeat a previous position.
The main component is a deep CNN over the game board configuration (precisely, a ResNet with batch normalization and ReLU). This network outputs two values:
: the probability of selecting a move over 19^2 _1 candidates.
: the winning probability given the current setting.
AlphaGo Zero is trained by self-play while MCTS improves the output policy further in every step.
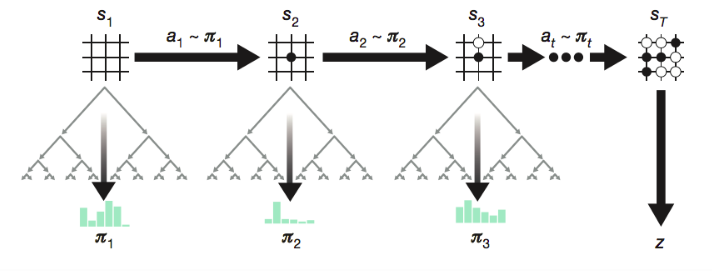
During self-play, MCTS further improves the action probability distribution and then the action
is sampled from this improved policy. The reward
is a binary value indicating whether the current player eventually wins the game. Each move generates an episode tuple
and it is saved into the replay memory.
The network is trained with the samples in the replay memory to minimize the loss:
where is a hyperparameter controlling the intensity of L2 penalty to avoid overfitting.
AlphaGo Zero simplified AlphaGo by removing supervised learning and merging seperated policy and value networks into one.