Representation Learning with Contrastive Predictive Coding
An overview of the paper “Representation Learning with Contrastive Predictive Coding”. The authors propose a universal unsupervised learning approach to extract useful representations from high-dimensional data, which they call Contrastive Predictive Coding. All images and tables in this post are from their paper.
The key insight of the model is to learn such representations by predicting the future in latent space by powerful autoregressive models. Despite the importance of unsupervised learning, it is yet to see a breakthrough similar to supervised learning: modeling high-level representations from raw observations remain elusive. Furthermore, it is not always clear what the ideal representation is and it it is possible that one can learn such a representation without additional supervision or specialization to a particular data modality.
One of the most common strategies for unsupervised learning has been to predict future, missing or contextual information. This idea of predictive coding is pretty old idea. Recent unsupervised learning has successfully used these ideas to learn word representations by predicting neighboring words.
Contrastive Predicting Coding
Motivation and Intuitions
The main intuition behind our model is to learn the representations that encode the underlying shared information between different parts of the (high-dimensional) signal. At the same time, it discards low-level information and noise that is more local. One of the challenges of predicting high-dimensional data is that unimodal losses such as meansquared error and cross-entropy are not very useful, and powerful conditional generative models which need to reconstruct every detail in the data are usually required. But these models are computationally intense, and waste capacity at modeling the complex relationships in the data , often ignoring the context
. For example, images may contain thousands of bits of information while the high-level
latent variables such as the class label contain much less information (10 bits for 1,024 categories). This suggests that modeling
directly may not be optimal for the purpose of extracting shared information between
and
. When predicting future information they instead encode the target
(future) and context
(present) into a compact distributed vector representations (via non-linear learned mappings) in a way that maximally preserves the mutual information of the original signals
and
defined as
By maximizing the mutual information between the encoded representations, they extract the underlying latent variables the inputs have in common.
Contrastive Predictive Coding
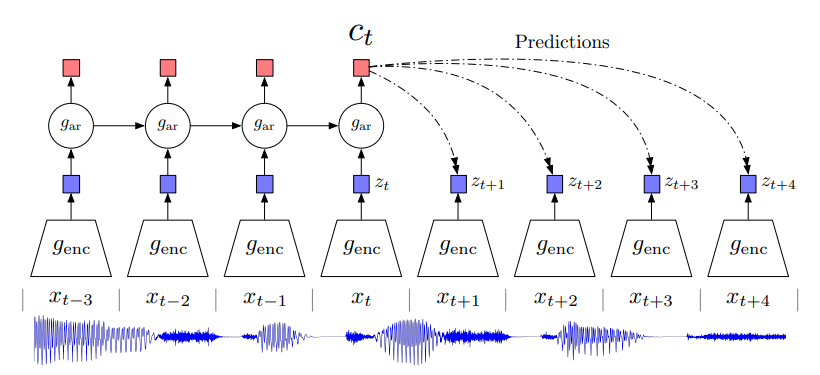
First, a non-linear encoder maps the input sequence of observations
to a sequence of latent representations
, potentially with a lower temporal resolution.
Next, an autoregressive model
summarizes all
in the latent space and produces a context latent representation
.
they do not predict future observations
directly with a generative model
. Instead, they model a density ratio which preserves the mutual information between
and
as follows:
they can use a simple log-bilinear model:
By using a density ratio and inferring
with an encoder, they relieve the model from modeling the high dimensional distribution
.
Overview of Contrastive Predictive Coding.
InfoNCE Loss and Mutual Information Estimation
Both the encoder and autoregressive model are trained to jointly optimize a loss based on NCE, which they call InfoNCE. Given a set of
random samples containing one positive sample from
and
negative samples from the ‘proposal’ distribution
Optimizing the above function will result in the final output estimating the density ratio. Furthermore, the authors showed that , which becomes tighter as
becomes larger.