Revisiting Training Strategies and Generalization Performance in Deep Metric Learning
An overview of the paper “Revisiting Training Strategies and Generalization Performance in Deep Metric Learning”. The authors review various deep metric learning methods and propose a simple, yet effective training regularization to boost the performance of ranking basaed DML methods. All images and tables in this post are from their paper.
Training a deep metric learning model
Learning visual similarity is important for a wide range of vision tasks, such as image clustering, face detection, or image retrieval. Measuring similarity requires learning an embedding space which captures images and reasonably reflects similarities using a defined distance metric. One of the most adopted classes of algorithms for this task is Deep Metric Learning (DML) which leverages deep neural networks to learn such a distance preserving embedding. The key components of a DML model can be broken down into 3 different parts:
Objective Function
The Deep Metric Learning, we learn an embedding function mapping datapoints
into an embedding space
which allows to measure the similarity between
as
with
being a predefined distance function. In order to train
to reflect the semantic similarity defined by given labels
, many objective functions have been proposed based on different concepts:
- Ranking-based: The most popular family are ranking-based loss functions operating on pairs, triplets or larger sets of datapoints. Learning
is defined as an ordering task, such that the distances
and positive
of the same class is minimized, and the distances
of the anchor with negative sample
- Classification-based: As DML is essentially solving a discriminative task, some approaches can be derived from softmax logits
. The goal here is to maximize the margin between classes.
- Proxy-based: These methods approximate the distributions for the full class by one or more learned representatives. By considering the class representatives for computing the training loss, individual samples are directly compared to an entire class. Additionally, proxy-based methods help to alleviate the issue of tuple mining which is encoutered in ranking-based loss functions.
Data Sampling
There are two broadly types of samplers, label samplers and embedded samplers. In label samplers, we choose a heuristic based on Samples per class (SPC-n). In SPC-R, we select
samples, and the last sample is made sure to have the same label as another existing sample. This ensures, that atleast one triplet exists in the batch. In embedded samplers, we try to create batches of diverse data statistics. The criteria used for this include:
- Greedy Coreset Distillation (GC): This criterion finds a batch by iteratively adding samples which maximize the distance from the samples that have been already selected.
- Matching of distance distributions (DDM): DDM aims to preserve the distance distribution of
. We randomly select m candidate mini-batches and choose the batch
with smallest Wasserstein distance between normalized distance histograms of
- FRD-Score Matching (FRD): Very similar to the previous approach. The only difference being, that we use frechet distance instead of Wasserstein distance.
Training parameters, regularization and architecture
- Architecture: In recent literature, mainly 3 architectures are used- GoogLeNet, Inception-BN and ResNet50.
- Weight Decay: Commonly, network optimization is regularized using weight decay/L2 Optimization.
- Embedding dimensionality: This is harder to compare and not justified in many works.
- Data Preprocessing: This definitely changes the entire model weights. Unfortunately, there is no proper comparison between different preprocessing steps.
- Batchsize: Batchsize determines the nature of the gradient updates to the networkHowever, it is commonly not taken into account as a influential factor of variation.
- Advanced DML methodologies: There are many extensions to objective functions, architectures, etc.However, although extensions are highly individual, they still rely on these components.
Analyzing DML training strategies
Studying DML parameters and architectures
In order to warrant unbiased comparability, equal and transparent training protocols and model architectures are essential, as even small deviations can result in large deviations in performance.
Evaluation of DML pipeline parameters and architectures.
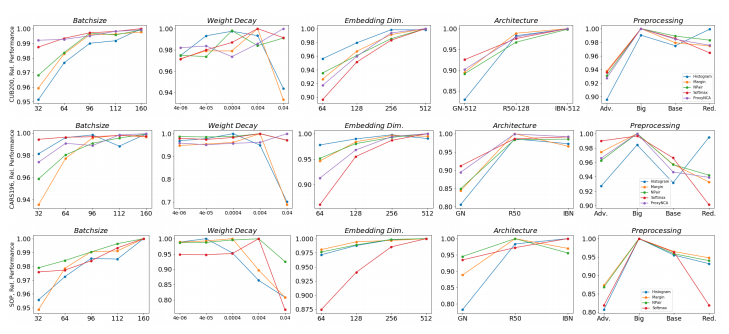
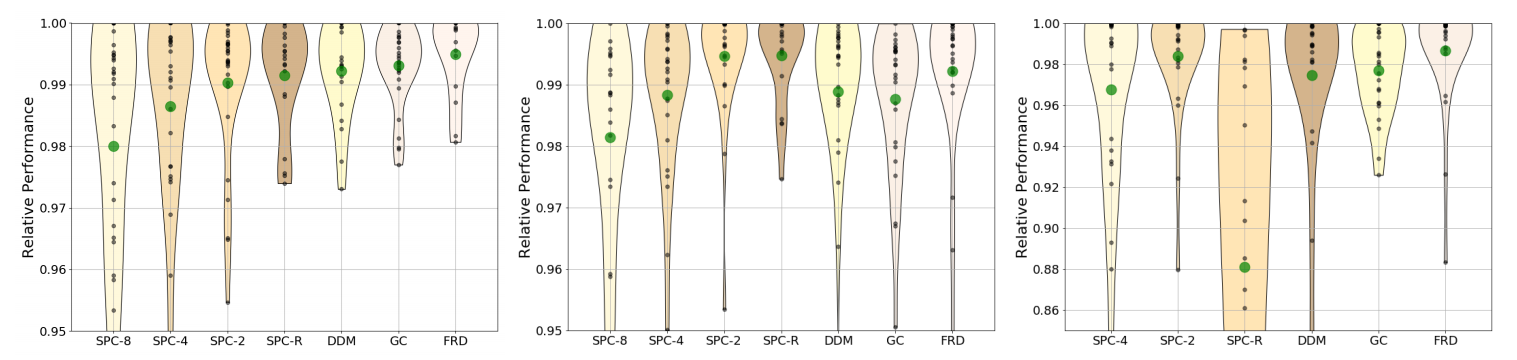
Batch sampling impacts DML training
Their study indicates that DML benefits from data diversity in mini-batches, independent of the chosen training objective. This coincides with the general benefit of larger batch sizes. While complex mining strategies may perform better, simple heuristics like SPC-2 are sufficient.
Comparison of mini-batch mining strategies.
Comparing DML models
Under the same setup, performance saturates across different methods, contrasting results reported in recent literature. Carefully trained baseline models are able to outperform state-of-the-art approaches which use considerable stronger architectures. Thus, to evaluate the true benefit of proposed contributions, baseline models need to be competitive and implemented under comparable settings.
Generalization in Deep Metric Learning
The experiments performed by the authors indicate that representation learning under considerable shifts between training and testing distribution is hurt by excessive feature compression, but may benefit from a more densely populated embedding space.
Rho-regularization for improved generalization
This is their proposed addition to the DML training. Implicitly regularizing the number of directions of significant variance can improve generalization.