Rich feature hierarchies for accurate object detection and semantic segmentation
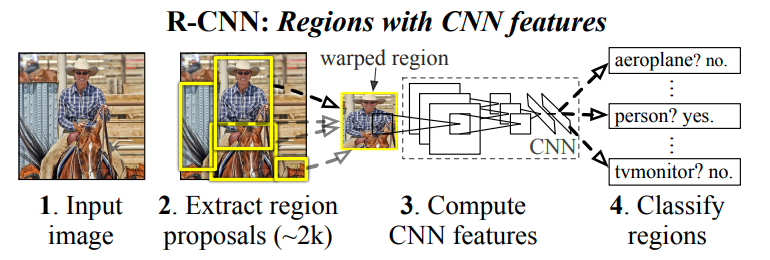
An overview of the paper “Rich feature hierarchies for accurate object detection and semantic segmentation”. The paper proposes a novel approach where the image is broken down into regions before being classified by the model. All images and tables in this post are from their paper.
Region proposals
There are various options available for this stage. The RCNN was initially built using selective search. The method here is agnostic, and any other method could also be used.
Feature extraction
Regardless of the size or aspect ratio of the candidate region, the authors warp all pixels in a tight bounding box around it to the required size. Prior to warping, they dilate the tight bounding box so that at the warped size there are exactly pixels of warped image context around the original box.
Testing
At test time, they run a selective search on the test image to extract around 2000 region proposals. Then, they warp each proposal and forward propagate it through the CNN in order to compute features. Then, for each class, the extracted feature vectors are scored using the SVM trained for that class. Given all scored regions in an image, we apply a greedy non-maximum suppression (for each class independently) that rejects a region if it has an intersection-over-union (IoU) overlap with a higher scoring selected region larger than a learned threshold.
Object Detection system overview.