Self training for few-shot transfer across extreme task differences
An overview of the paper “Self training for few-shot transfer across extreme task differences”. The authors propose a new approach to overcome large domain gap between base dataset and target dataset. All images and tables in this post are from their paper.
Usually, all few-shot leanring techniques must be pre-trained on a large, labeled “base dataset”. In problem domains where such large labeled datasets are not available for pre-training (e.g., X-ray images), one must resort to pre-training in a different “source” problem domain (e.g., ImageNet), which can be very different from the desired target task.
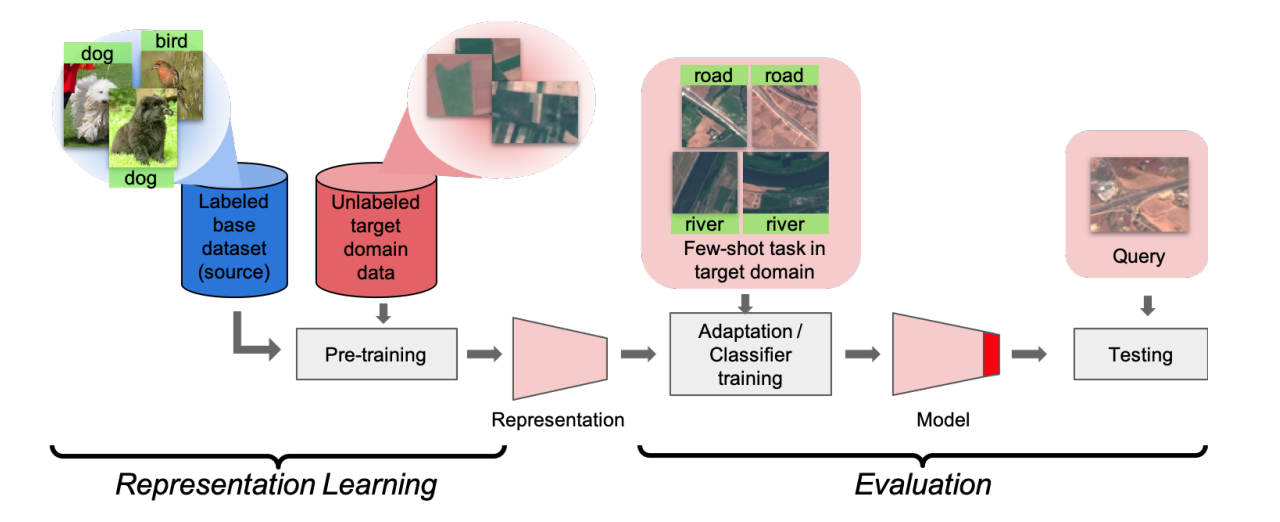
In this paper, they propose a methodology where the model can be divided into two sections. The first model uses the labeled base dataset and the unlabeled target domain data for representation learning. This step is similar to pre-training. The second part of the model is used for evaluation and classifying samples.
Problem Setup
The goal is to build learners for novel domains that can be quickly trained to recognize new classes when presented with very few labeled data points. Formally, the target domain is defined by as set of data points , an unknown set of classes
, and a distribution
over
. A “few-shot learning task” will consist of a set of classes
, a very small training set (“support”)
and a small test set (“query”)
When presented with such a few-shot learning task, the learner must rapidly learn the classes presented and accurately classify the query images.
As with prior few-shot learning work, we will assume that before being presented with few-shot learning tasks in the target domain, the learner has access to a large annotated dataset known as the base dataset. However, unlike prior work on few-shot learning, we assume that this base dataset is drawn from a very different distribution.
Workflow of proposed framework.
Approach
During the representation learning stage, the model performs three steps:
- Learn a teacher model
on the base dataset
by minimizing cross entropy loss.
- Use the teacher model to construct a softly-labeled set
for all the unlabeled data available such that
.
- Learn a student model
by optimizing the loss
where is a type of contrastive loss to help the learner extract additional useful knowledge specific to the target domain.
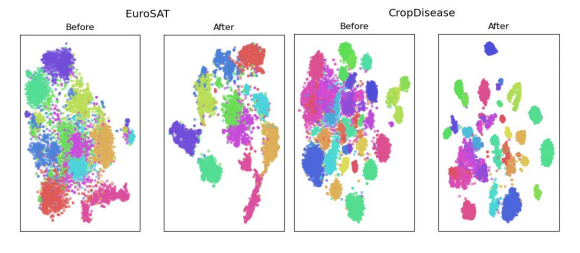
t-SNE plot of EuroSAT and CropDisease prior to and after model.
Evaluation
Here, we freeze the representations after performing the representation learning and train a linear classifier on the support set and evaluate the classifier on the query set. Furthermore, here, the student is initialized to the teacher embedding with a randomly initialized classifier by default.
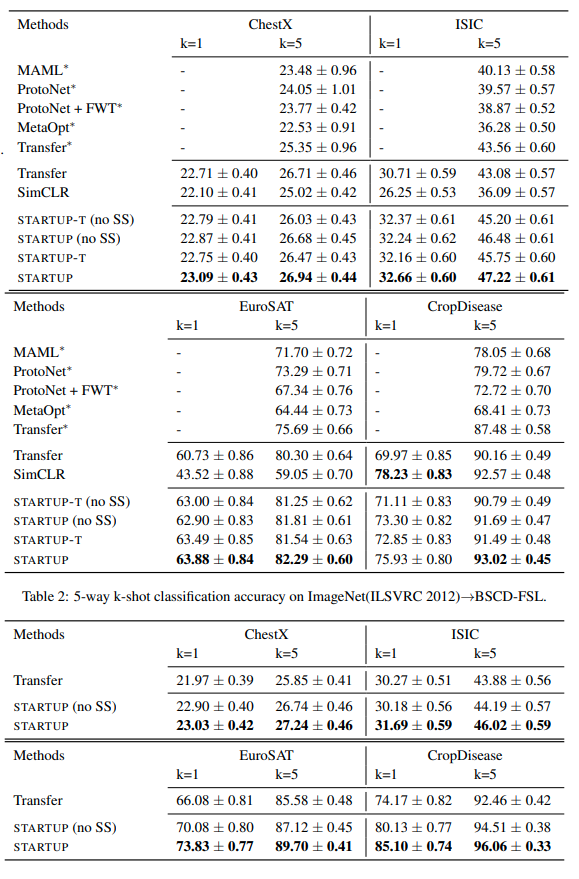
Performance of the model on different datasets.