Siamese Neural Networks for One-shot Image Recognition
An overview of the paper “Siamese Neural Networks for One-shot Image Recognition”. The authors propose a novel approach for one shot learning which can be learned with very few training examples. In general, we learn image representations via a supervised metric-based approach with siamese neural networks, then reuse that network’s feature for one-shot learning without any retraining. All images and tables in this post are from their paper.
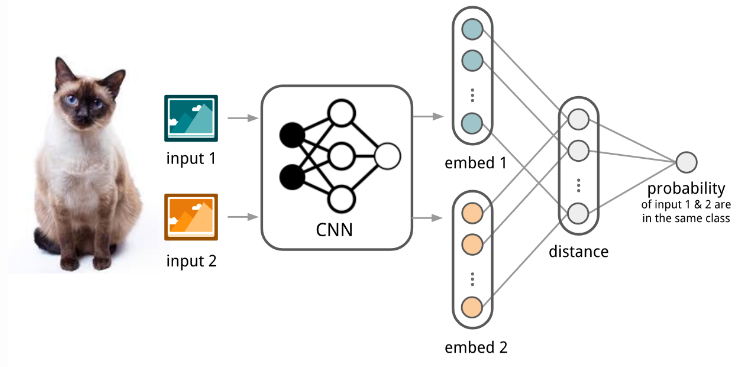
Siamese Network
A siamese neural network consists of twin networks which accept distinct inputs but are joined by an energy function at the top. This function computes some metric between the highest level feature representation on each side. The parameters between the twin networks are tied. Weight tying guarantees that two extremely similar images could not possibly be mapped by their respective networks to very different locations in feature space because each network computes the same function. Also, the network is symmetric, so that whenever we present two distinct images to the twin networks, the top conjoining layer will compute the same metric as if we were to we present the same two images but to the opposite twins. The loss typically used in these experiments are triplet loss, contrastive loss, etc. These losses tend to optimize the network in such a way that similar examples are grouped as close as possible and the different ones are as far away as possible. Both the images (in this case) pass through the siamese network. The loss is then computed after both forward passes are completed followed by backpropagation. The one shot verification step is computed with a simple metric such as cosine similarity, etc. The best class is then predicted as the answer.
The architecute of convolutional siamese neural network for few-shot image classification.