The effects of negative adaptation in Model-Agnostic Meta-Learning
An overview of the paper “The effects of negative adaptation in Model-Agnostic Meta-Learning”. The author points out that the adaptation algorithm like MAML can significantly recrease the performance of an agent in a meta-reinforcement learning setting, even on a range of meta-learning tasks. All images and tables in this post are from their paper. The capacity of meta-learning algorithms to quickly adapt to a variety of tasks, including ones they did not experience during meta-training, has been a key factor in the recent success of these methods on few-shot learning problems. This particular advantage of using meta-learning over standard supervised or reinforcement learning is only well founded under the assumption that the adaptation phase does improve the performance of our model on the task of interest. However, in the classical framework of meta-learning, this constraint is only mildly enforced, if not at all, and we only see an improvement on average over a distribution of tasks.
Introduction
Humans are capable of learning new skills and quickly adapting to new tasks they have never experienced before, from only a handful of interactions. Likewise, meta-learning benefits from the same capacity of fast learning in the low-data regime. The main advantage of using meta-learning over standard supervised or reinforcement learning relies on the premise that this adaptation phase actually increases the performance of our model. Howecer, there is no guarantee that the adaptation phase shows some improvement at the scale of an individual task.
MAML in RL
Reinforcement Learning
In this paper, the authors only consider the meta-reinforcement learning setting in this paper. In the context of meta-RL, a task is defined as a Markov Decision Process. For some discount factor
, they return
at time
is a random variable corresponding to the discounted sum of rewards observed after
following a policy
.
where is the random reward received after taking action
in state
.
In meta-RL, low data regime corresponds to having limited amount of interactions with the task of interest.
MAML
In this paper, the authors are interested in a meta-learning method based on parameter adaptation and inspired by fine-tuning called MAML (Model Agnostic Meta-Learning). The idea of MAML is to find a set of initial parameters of our policy
, such that only a single step of gradient descent is necessary to get new parameters
, where the corresponding policy
is adapted on the task
. More precisely, given a dataset
of trajectories samples from task
, following the policy
, and a corresponding loss function
, MAML returns new parameters
defined as:
Negative Adaptation
The minimization of the meta-objective loss only encourages the adaptive policy to have a high expected return, without any consideration of the policy we started with. There is no incentive for MAML to produce adapted parameters that improve performance on the task of interest over the initial policy.
The regime on which MAML shows negative adaptation seems to correspond to velocities where the return of the initial policy is already at its maximum. Intuitively, the meta-learning algorithm is unable to produce a better policy because it was already performing well on those tasks, leading to this decrease in performance. The authors believe that this overspecialization on some tasks could explain the negative adaptation.
Negative Adaptation example.
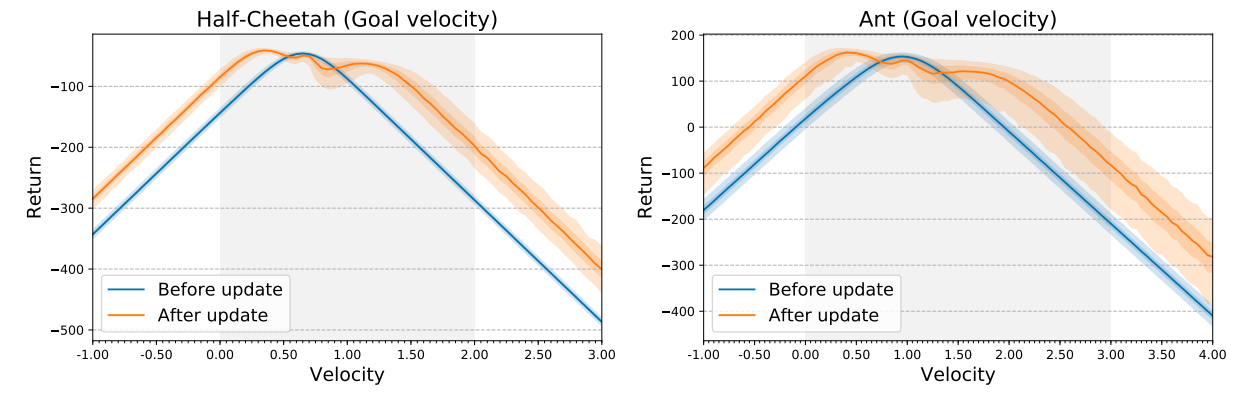
Discussion
In order to mitigate the effects of negative adaptation, we need to include a constraint on the improvement in our definition of the meta-objective. To characterize the improvement more precisely for a fixed task , the authors introduce a random variable
, which is the difference between the returns of the policies before and after the parameter update:
Avoiding the negative adaptation translate to havin , with high probability. Ideally, we would like to enforce this constraint over all tasks. However, in early experiments on MAML with this modified meta-objective, the authors were not able to significantly reduce the effect of negative adaptation, and more research is necessary.