Towards Causal VQA
An overview of the paper “Towards Causal VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing”. Despite significant success in Visual Question Answering (VQA), VQA models have been shown to be notoriously brittle to linguistic variations in the questions. In this work, the authors propose a method to add synthetic data to the dataset to make predictions more robust. All images and tables in this post are from their paper.
Introduction
In these applications we expect a model to answer truthfully and based on the evidence in the image and the actual intention of the question. Instead of “sticking to the facts”, models frequently rely on spurious correlations and follow biases induced by data and/or model. While previous works have studied linguistic modifications, this work’s contribution is the first systematic study of automatic visual content manipulations at scale. Analogous to rephrasing questions for VQA, images can also be semantically edited to create different variants where the same question-answer (QA) pair holds. The author’s motivation to create this complementary dataset stems from the desire to study how accurate and consistent different VQA models are and to improve the models by the generated ‘complementary’ data (otherwise not available in the dataset).
VQA models change their predictions as they exploit spurious correlations rather than causal relations based on the evidence. Shown above are predictions of 3 VQA models on original and synthetic images from our proposed IV-VQA and CV-VQA datasets. ‘Ours’ denote the models robustified with our proposed data augmentation strategy.
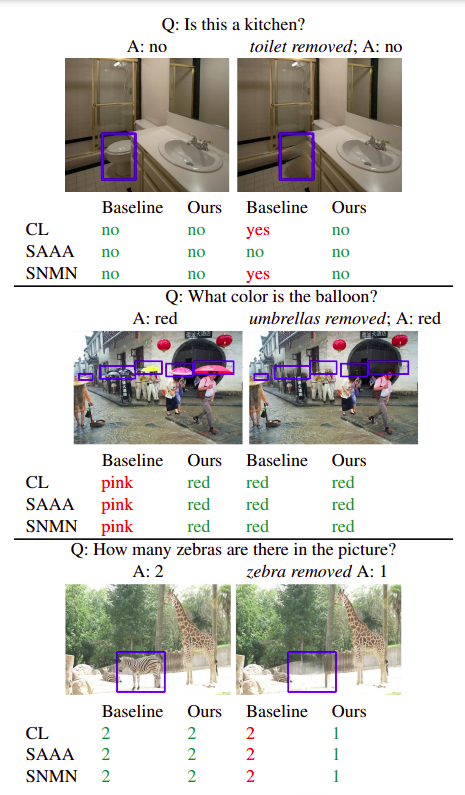
Synthetic Dataset for Variances and Invariances in VQA
While robustness w.r.t linguistic variations and changes in answer distributions have been studied, we explore how robust VQA models are to semantic changes in the images. For this, we create a synthetic dataset by removing objects irrelevant and relevant to the QA pairs and propose consistency metrics to study the robustness.
Invariant VQA (IV-VQA)
For the creation of this dataset, we select and remove the objects irrelevant to answering the question. Hence the model is expected to make the same predictions on the edited image. A change in the prediction would expose the spurious correlations that the model is relying on to answer the question.
CoVariant VQA (CV-VQA)
An alternate way of editing images is to target the object in the question. Object-specific questions like counting, color, whether the object is present or not in the image are suitable for this type of editing.
Conclusion
The authors propose a semantic editing based approach to study and quantify the robustness of VQA models to visual variations. Their analysis shows that the models are brittle to visual variations and reveals spurious correlation being exploited by the models to predict the answer. Finally, they propose a data augmentation based technique to improve models’ performance.